0 Density-Based Clustering
👍🏻 gd) 다양한 모양의 클러스터 발견 可
👍🏻 gd) 1 scan -> efficient
👍🏻 gd) nosie를 다룰 可
❓ why) 거리, 계층 기반의 클러스터링 방법들은 noise, outlier를 효과적으로 다룰 수 없다. 밀도 기반의 클러스터링 방법은 outlier를 다룰 수 있다.
🥲 pb) hyper-param. 설정
1. Hyper-parameters
- : 반경
반경 내에서 이웃하는 점의 개수를 세게 된다.- : minimum number of points
반경 내의 이웃이 MinPts 이상이면 high density를 가진다고 한다.
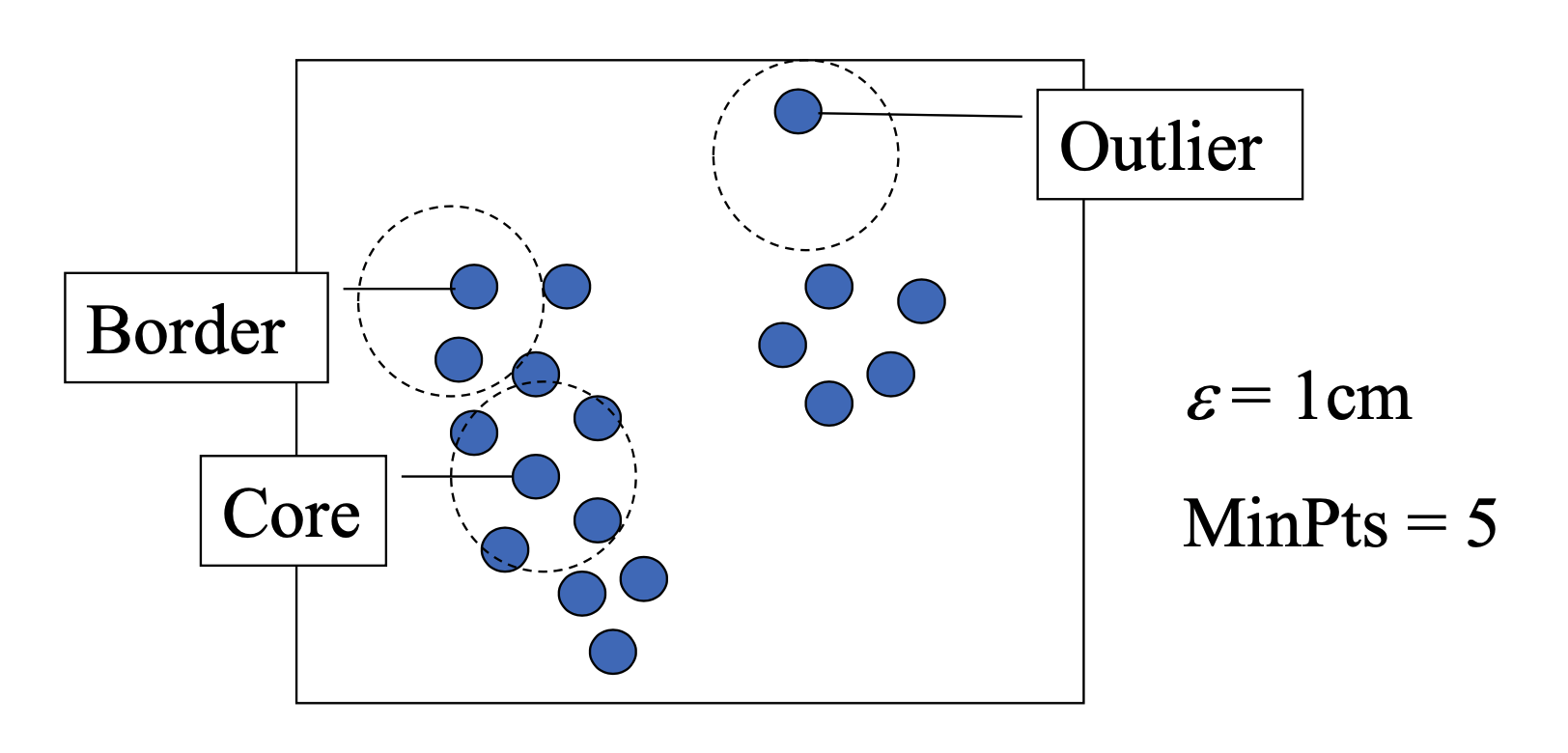
2. Type of Points: Core, Border, Outlier
- Core points: 위의 식을 만족하는 데이터 포인트
- Border points: 위의 식을 만족하지 않는, Core point의 neighbor
- Outlier : noise, not core, not border
3. Directly Density-Reachable
if is a core point and ,
is directly density-reachable.
4. Density-Reachable
1 DBSCAN
👍🏻 gd) 모양 多, 크기 多
👍🏻 gd) outlier 다룰 수
👍🏻 gd) 클러스터 개수가 자동적으로 정해진다.
🥲 pb) hyperparam
2 OPTICS
Ordering Points To Identify the Clustering Structure
☑️ what) 를 선택하기 위해 dendrogram과 같이 클러스터링 구조를 보여주는 시각화된 정보이다. 클러스터를 실제로 생성하는 것이 아니다.
how)algorithm
