트라이 Trie
입력되는 문자열을 Tree 형식으로 만들어 진행되어 보다 빠르게 문자열 검색이 가능한 자료구조
문자열을 검색하는 문제에서 입력되는 문자열이 많을 경우 자주 사용
해설참고 Lv 3. 금과 은 운반하기
풀이
가능한 범위가 넓기 때문에 이분탐색으로 훑어야한다. 여기까진 캐치했지... 근데 주어진 시간이 이분탐색의 기준이 되고, 금/은을 나눠서 가져오는 과정에서 구현이 안되서 다른 풀이를 참고했다. 프로그래머스 AI 추천 잘하네... 어쩜 이리 잘 못 푸는 문제만 쏙쏙^^...
Lv 3는 언제쯤 잘 풀릴까...
코드
def solution(a, b, g, s, w, t):
start = 0
end = 10**9*4*10**5 # 최대 필요량(10**9) * 금,은 2번 왕복(4) * 최소무게(1) * 최대시간(10**5)
# 최솟값을 찾아야하므로 최댓값에서 시작
answer = end
while start <= end:
mid = (start+end)//2
gold = 0
silver = 0
total = 0
for i in range(len(g)):
now_gold = g[i]
now_silver = s[i]
now_weight = w[i]
now_time = t[i]
# 현재 마을에서 옮길 수 있는 총 횟수 (왕복으로 계산)
move_cnt = mid // (now_time * 2)
# 만약 나머지가 now_time보다 크면 1번 편도 가능하므로 1번 더 계산
if mid % (now_time*2) >= now_time:
move_cnt += 1
# move_cnt(운반횟수) * now_weight(한번에 옮길수있는 무게) = 총 운반할수있는 양
# gold, silver, total에 각각 더하는 값은, 보유량(now_g, now_s)과 왕복으로 옮기는 총량(move_cnt * now_w) 중 최소값
gold += now_gold if (now_gold < move_cnt * now_weight) else move_cnt * now_weight
silver += now_silver if (now_silver < move_cnt * now_weight) else move_cnt * now_weight
total += now_gold + now_silver if (now_gold + now_silver < move_cnt * now_weight) else move_cnt * now_weight
# 모두 옮길 수 있는 충분한 시간이었음
if gold >= a and silver >= b and total >= a + b:
end = mid - 1
answer = min(answer, mid)
else:
start = mid + 1
return answer해설참고 Lv 4. 자동완성
풀이1 (정렬로 처리)
예전에 비슷한 문제를 풀어본 적이 있었다. 접두사가 같은 단어를 체크해주는 그런 문제였던 것 같은데 거기서 정렬로 문제를 처리해줬던 게 생각났음...! 근데 구현은 직접 못했다 다른 사람 코드 보면서 연습하다보면 늘겠거니 한다...
참고한 블로그는 여기
등장하는 단어를 모두 정렬하면 인접한 2개의 단어가 비슷한 글자가 등장할 수 있는 단어다. 따라서 앞, 뒤 단어를 살펴보면서 일치한 글자수+1의 최댓값을 가져오면 된다.
코드1
def solution(words):
N = len(words)
words.sort() # 단어를 사전순으로 정렬
result = [0] * N # 단어마다 입력해야 하는 문자 수
for i in range(N - 1):
# 인접하는 두 단어 비교
now_word = words[i]
next_word = words[i + 1]
for j in range(min(len(now_word), len(next_word))):
if now_word[j] != next_word[j]:
j -= 1 # 일치하지 않으면 일치하는 최대 인덱스로 저장 후 break
break
# 일치하는 인덱스 + 1만큼 문자를 입력해야 찾을 수 있다
# (j는 0부터 시작하니 +1)
# 단, 입력하는 문자 수가 단어 길이를 넘으면 안됨
result[i] = max(result[i], min(len(now_word), j + 2))
result[i + 1] = max(result[i + 1], min(len(next_word), j + 2))
# 합계가 검색결과 총 횟수
return sum(result)풀이2 (트라이)
트라이 자료구조를 사용하면 훨씬 깔끔하게 풀 수 있다
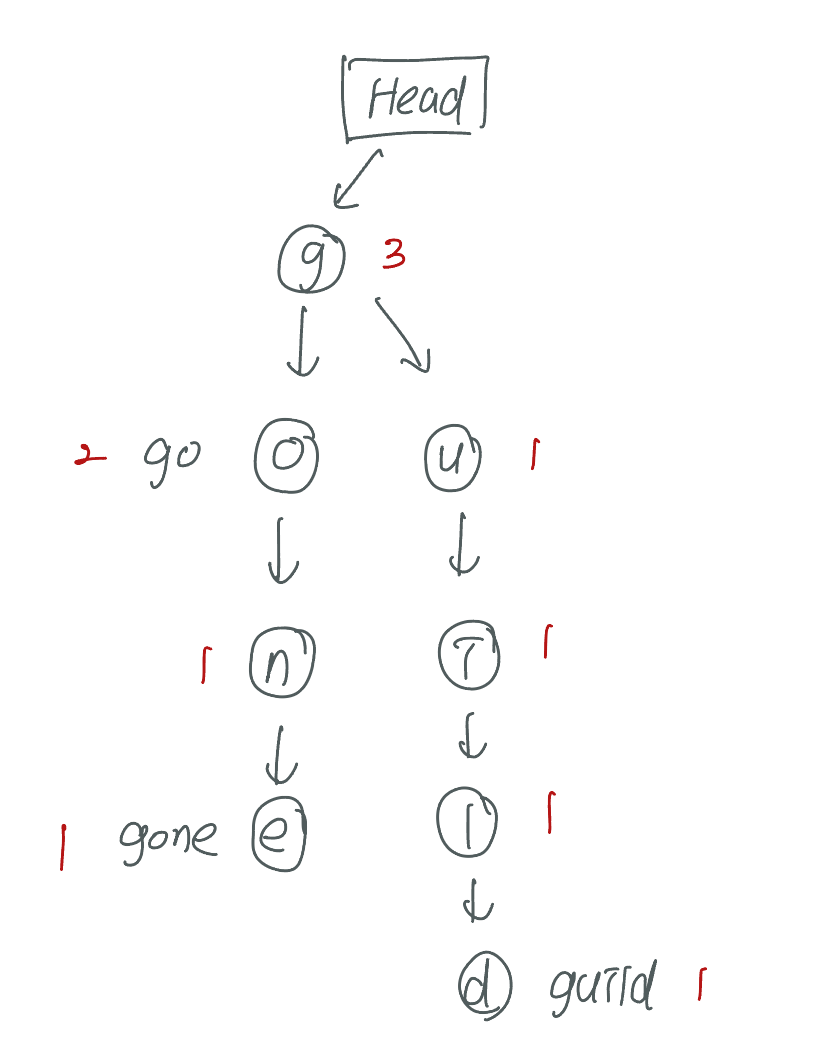
글자별로 (letter, [0, {}]) 의 자료를 만들어서 몇개의 글자가 등장하는지 세어주고 이어붙여준다
위와 같이 등장하는 글자로 트리를 만들어주면서 해당되는 데이터가 뭔지 체크해준다!
{'g': [3, {'o': [2, {'n': [1, {'e': [1, {}]}]}], 'u': [1, {'i': [1, {'l': [1, {'d': [1, {}]}]}]}]}]}
이 분 블로그도 나중에 참고해서 공부해야지
코드2
def make_trie(words):
dic = {}
for word in words:
current_dict = dic
for letter in word:
current_dict.setdefault(letter, [0, {}])
current_dict[letter][0] +=1
current_dict = current_dict[letter][1]
return dic
def solution(words):
answer = 0
trie = make_trie(words)
for word in words:
temp = trie
for letter in word:
answer += 1
temp = temp[letter]
if temp[0] == 1:
break
else:
temp = temp[1]
return answer오늘 푼건 거의 다 해설을 보고 했군... 어렵다
