Kafka troubleshooting 사례 @ 2021 LINE DEVDAY
개요
2021년 LINE DEVELOPER DAY에서 Haruki Okada님이 발표해주신 내용이다.
전체 영상은 여기에서 볼 수 있다.
최근에 봤던 troubleshooting 사례 중에 가장 흥미진진하고 시원한 영상이라 정리해보고 싶었다.
Kafka @ Line

LINE에서 가장 많이 쓰이는 분산 스트리밍 middleware중 하나다. 높은 scalability 뿐만 아니라 ACL, quota와 같은 multi-tenant한 운용도 가능하다.
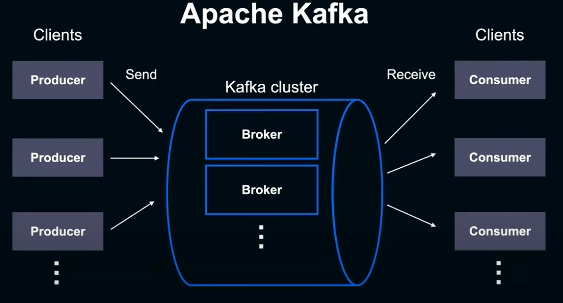
하나의 Kafka cluster는 일반적으로 여러개의 broker로 구성된다. 이 Kafka에 메시지를 보내는쪽을 producer, 메시지를 받고 처리하는 쪽을 consumer라 한다.
당시 LINE에서는 단일 Kafka cluster를 여러 서비스에서 공유하는 multi-tenant model을 사용중이었다. 서비스 수는 100개 이상, 메시지 유입 peak는 15M/s, 일일 데이터 송수신량은 1.4PB에 달했다.
Overview of the phenomenon
어느날 Kafka 설정 변경을 rollout하기 위해 rolling restart를 하던 중, 어떤 개발자로부터 현재 자신들의 서비스에서 Kafka 메시지 produce가 실패하기 시작했다는 보고를 받았다.
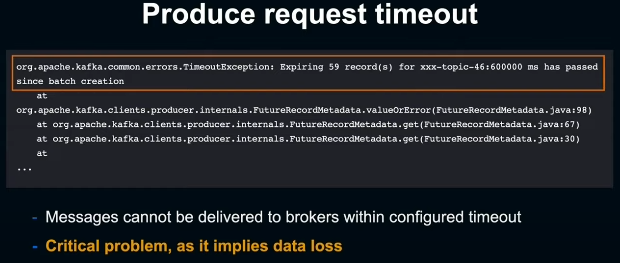
설정된 시간내에 Kafka에 메시지를 보내지 못했다는 뜻으로 이는 곧 data loss로 이어지기에 굉장히 critical 했다.
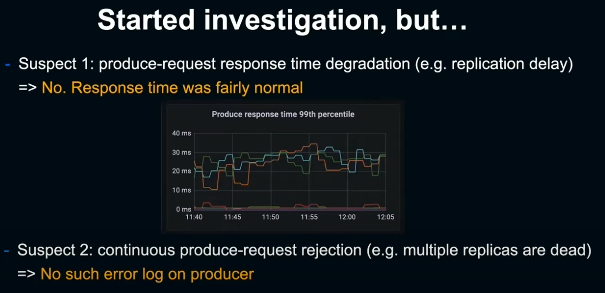
처음 의심한건 replication delay로 인한 produce-request response time degradation. 하지만 관련 metric은 문제가 없었다. 다음으로 replica가 여러개 죽어서 지속적인 produce-request rejection이 발생하는거 아닌가 했지만, 이 역시 별다른 에러 로그는 보이지 않았기에 해당되지 않았다.

조사를 더 해보니 기묘한 현상이 관측되었다. broker 측의 response time은 정상적이었으나 producer 측의 request latency는 16초 이상으로 관측되었다. 그리고 restart를 막 한 broker로의 request만 비정상적인 latency를 보인다는 것을 알게되었다.
정리하면, 어떤 broker를 restart 했을때 produce-request latency가 현저하게 악화되기 시작했으나 해당 broker측의 response time metric들은 지극히 정상적이었다.
이 시점에선 근본적인 원인을 전혀 알 수 없었기에, data loss를 막고자 broker를 한번 더 restart하여 문제를 해결했다. 하지만 이로인해 사후분석에 활용할 정보들이 많이 날아가게 되었다.
Investigation
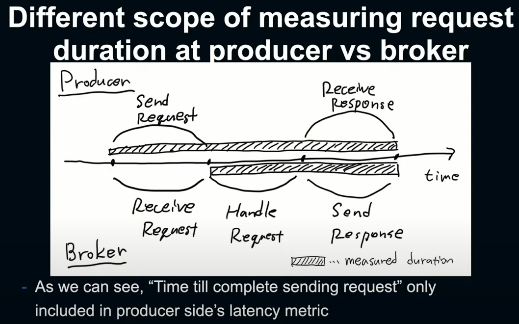
재발을 방지하고자 근본적인 원인을 규명하고자 했다. 먼저 producer와 broker간 response time metric이 큰 차이를 보였는데, Kafka 코드를 확인해보니, request 송신 자체에 시간이 걸리면 이런 차이가 발생한다는 가설을 세울 수 있었다.
producer측에서는 request를 보내기 시작해서 broker가 이를 받아 모두 처리하고 response까지 모두 받는 시간을 response time metric으로 계산하는 반면,
broker측에서는 request를 모두 받고 난 이후부터 처리 한 뒤 response까지 모두 보내는 시간을 response time metric으로 잡고 있어서,
어떤 이유로 request 송신에 시간이 많이 걸린다면 broker측에서는 나타나지 않는 것이었다.
가설 1. Producer's I/O thread got stuck

이와같은 request 송신 자체의 지연. 이것을 일으키는 원인으로 우선 producer의 sender thread이라는 non-blocking I/O thread가 어떤 이유로 stuck되고 말았다라는 가설을 세워봤다. 이 가설을 검증하기 위해 producer측의 DEBUG 레벨의 로그와 JVM async-profiler를 producer측에 붙여 상세한 정보들을 얻어야 했다. 해당 이슈를 겪은 서비스 개발자에게 협조를 구해 재현 실험을 해보기로 했다.
구체적으로는,
profile을 수집할 준비를 해두고, 재현되었을 때 신속하게 대응할 수 있도록 모니터링 한다.
그리고 문제가 되었던 broker를 다시 한번 재현할때까지 몇번 restart 한다는 것이다.
그러나, 몇번 broker를 restart 해봤는데 결국 현상을 재현할 수 없었다. 현재 수집한 정보도 너무 적고 재현성도 너무 낮아, producer가 어떤 이유로 stuck되었는지 검증하는게 생각보다 더 어려웠음을 알게 되었다.
가설 2. Network performance degradation

다음으로 request 송신 자체의 지연을 일으킬 수 있는 원인으로 문제가 발생한 broker와 producer 간 네트워크 경로의 성능 이슈가 문제 아닐까 하는 가설을 세워봤다.
이를 위해 간단히 ping을 해봤는데 지극히 정상적이었다. 이 밖에도 TCP retransmission과 bandwidth saturation도 살펴봤지만 별 다른 점은 없었다.
TCP SYN Cookie spike
조사가 난항을 거듭하던 중, 지난번 이슈와 다른 서비스, 다른 broker에서 똑같은 이슈가 재발했다. 몇번 이러한 이슈가 발생하여 여러 사례들의 정보를 수집할 수 있었고, request 지연을 일으킬 수 있는 공통된 패턴이 있는지 찾아보기로 했다.
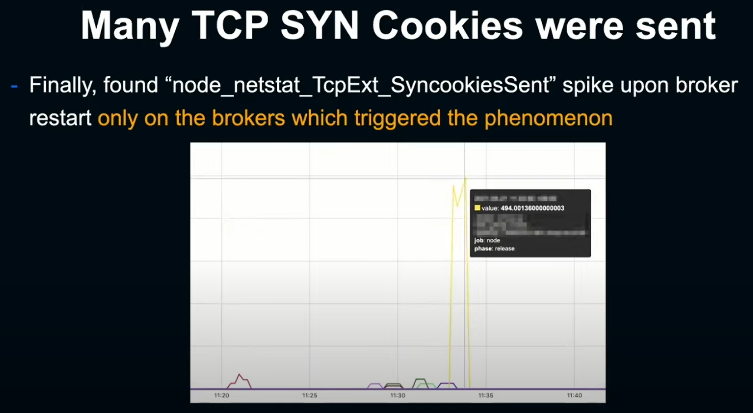
많은 metric들을 주의깊게 하나하나 살펴보니 broker를 restart 했을 때, node_exporter의 SyncookiesSent가 현저한 spike를 나타낸단 사실을 알게 되었다.
이 SyncookiesSent의 상승이 무슨 의미인지 알기 위해선, TCP SYN Cookies에 대해 간략히 알아볼 필요가 있다.
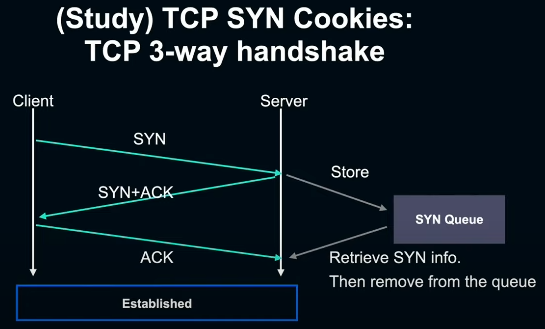
TCP SYN Cookies는 SYN flood 공격에 대응하기 위한 메커니즘으로, 우선 TCP 3-way handshake부터 복습해보자.
TCP에서는 client가 connection을 열고 싶을때, 다음과 같이 동작한다.
1. Client -> Server 로 SYN 송신
2. Server는 (1)의 SYN을 SYN queue에 추가한 뒤, Server -> Client 로 SYN+ACK 송신
3. Client -> Server 로 ACK 송신
4. Server는 (2)의 SYN을 queue에서 꺼내와 connection 수립. handshake 완료
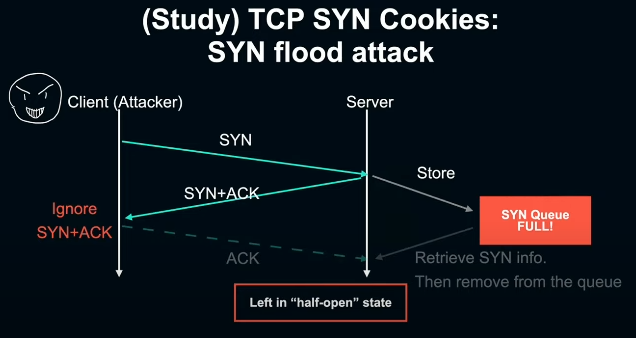
SYN flood 공격에서는 악의를 가진 client가 대량의 SYN 패킷을 server 쪽으로 보낸다. 여기서 handshake의 마지막 단계로 server로 부터 받은 SYN+ACK에 응답해 server로 ACK를 송신해야 하는데 이것을 고의적으로 무시하면, server는 계속 완료되지 않은 SYN을 SYN queue에 적재하게 되고 언젠가 꽉 차버리게 되면 정상적인 client의 연결도 못하게 막아버리는 일종의 DoS 공격인 셈이다.
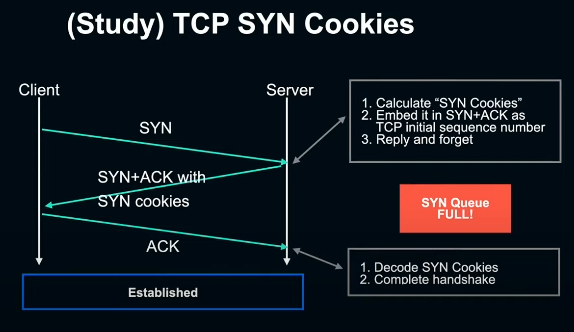
TCP SYN Cookies는 이러한 상황에서도 client의 접속을 할 수 있도록 하기 위한 구조다. 여기서는 리눅스 커널을 전제로 이야기 하겠다. SYN flood를 받아 SYN queue가 꽉 차게 되면, 리눅스 커널은 SYN 패킷을 SYN queue에 넣는 대신, SYN에 포함된 정보를 TCP initial sequence number에 인코딩해 SYN+ACK 패킷에 내장시켜 client에 보내 reply-and-forget 해버린다. 나중에 client가 SYN+ACK를 받아 ACK를 다시 보내면 여기에 인코딩된 sequence number로부터 SYN Cookie를 디코딩 해 connection을 수립하고 handshake를 완료시킨다.
따라서 앞서 발생한 SyncookiesSent metric의 spike는 client로부터 SYN을 받았지만 SYN queue가 꽉 차있어 대신 SYN Cookies를 보내 평소와 다른 방식으로 handshake한게 급증했음을 의미했다. 즉 broker가 당시 SYN flood 상태에 있었다는 것이다.

왜 SYN flood가 일어났을까? 문제가 발생한 broker를 포함해 LINE의 multi-tenant cluster에서는 broker 하나에 여러개의 producer와 consumer와 같은 client들이 접속해 있는 상태다. 여기서 broker를 restart 했을 때, 이 broker에 접속해 있던 client connection들은 다른 broker들에게 fail-over 되고, restart가 끝나게 되면 원래 접속해 있던 client들은 한번에 원래 broker에 다시 접속한다.
문제가 발생한 broker에는 18k 이상의 client로부터 connection을 갖고 있었기 때문에 이러한 일이 일어난 것은 자연스럽다고 생각했다.
이렇게 broker가 SYN flood 상태가 되면서 일부 client들의 handshake가 SYN Cookie를 사용하는 flow에 fallback되었음을 알게 되었다.
사실 SYN Cookie가 TCP throughput에 악영향을 미친 케이스가 있다는 건 이미 알려져 있다. 무슨 뜻인지 알아보기 위해 TCP window에 대해 잠시 복습하고 넘어가겠다.
TCP window
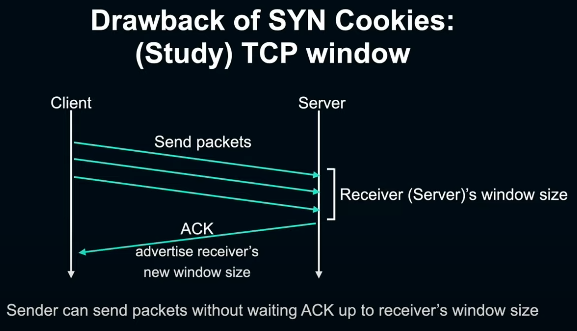
TCP window는 TCP에서 유량제어를 하기 위한 시스템이다. 일반적으로 TCP의 수신단에서 현재 얼마나 많은 데이터를 수신할 수 있는지 TCP 패킷에 반영해 송신단에 advertising하여 송신량을 조절할 수 있게 해준다. 송신단은 수신단에서 advertising된 window size까지는 수신단의 ACK을 기다리지 않고 패킷을 한꺼번에 전송할 수 있다.

window size는 16bit로 TCP 스펙에 명세되어 65535의 최대치를 갖게 된다. 즉 서버를 수신단으로 가정해보면, 서버에서의 ACK을 기다리지 않고 한꺼번에 전송할 수 있는 데이터 양이 최대 65535 byte가 된다. 이 한계치는 인터넷과 같이 round-trip이 큰 환경에선 병목이 될 수 있겠다.
TCP window scaling
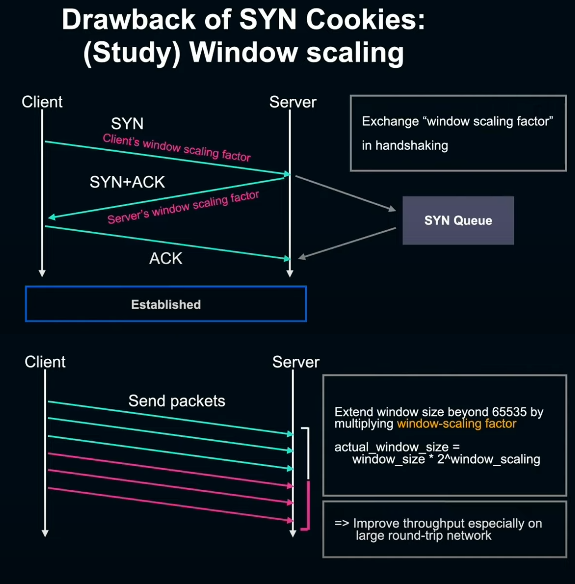
이 때 window size를 65535 이상으로 확대하고 throughput을 향상시키기 위해 사용되는 것이 window scaling이다. window scaling은 TCP handshake시 SYN과 SYN+ACK에 scaling factor 수치를 상대에게 advertising하여 실제 데이터를 송수신할때 window size에 만큼을 곱해 계산한다. 이를 통해 window size를 65535보다 크게 확대하고 ACK을 기다릴 필요 없이 한꺼번에 전송할 수 있는 데이터량이 늘어나 throughput의 향상을 기대할 수 있다.
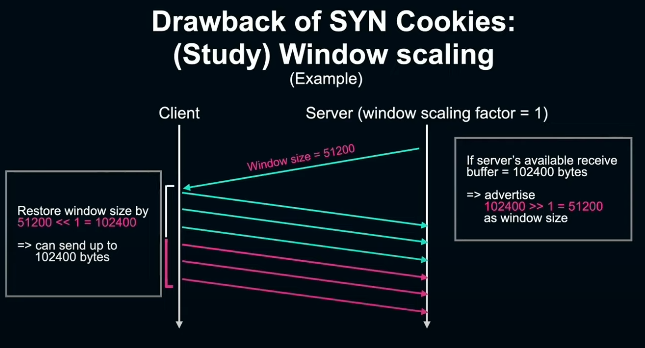
한가지 예를 들어보겠다. handshake를 할 때, server에서 client로 미리 window scaling factor를 1로 advertising한다고 해보자. 이 때, server가 client단에 대해 window size를 102400 advertising한다고 하면 16bit가 넘는 값이라 불가능하다. 대신 102400 >> 1을 한 51200을 window size로 패킷에 반영해 advertising한다. 다시 client에서는 여기에 51200 << 1을 해 102400를 복원한다. 이와 같은 방식으로 65535 이상의 window size를 advertising 할 수 있다.
여기까지 window size와 window scaling에 대한 복습해봤다.

다시 SYN Cookie에서 throughput이 떨어지는 이야기로 돌아가자. SYN Cookie란 SYN queue에 SYN 패킷을 보관하는 대신 SYN 정보를 교묘하게 TCP sequence number로 인코딩하는 임베디드 시스템이다. 그런데 sequence number는 32bit에 불과해 내장할 수 있는 정보가 제한되어 있어 window scaling factor를 임베디드 할 수 있는 곳이 없다. 다시 말해 SYN Cookie로 handshake를 할 경우 window scaling을 사용할 수 없게 된다. 따라서 SYN Cookie를 사용하는 flow를 타게되면 ACK을 기다리지 않고 한꺼번에 보낼 수 있는 데이터 양이 적어져 throughput이 감소하게 된다.
그렇다면 이것이 produce-request latency의 원인일까? 결론을 내리기엔 아직 이르다. SYN Cookie에서의 TCP throughput 악화는 window scaling factor를 내장할 수 있는 공간이 없기 때문에 window scaling을 사용하지 못하며 발생한다.
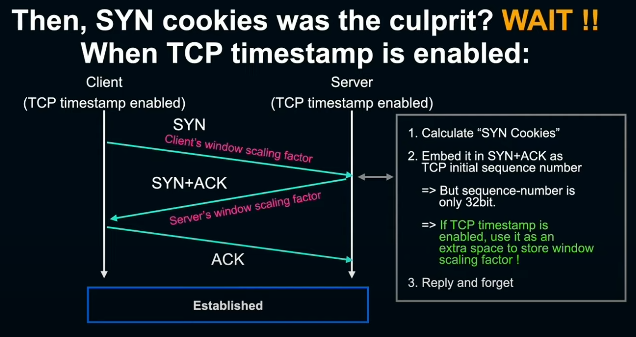
그러나 사실, 리눅스 커널은 TCP timestamp가 유효한 경우, timestamp field를 여분으로 사용해 window scaling factor를 내장하는 기능이 있다. 또한 당시 환경에서 TCP timestamp는 default로 유효했기에 앞서 살펴본 throughput의 악화를 일으키는 원인으로 짚기엔 무리가 있었다.

게다가 아무리 window scaling factor가 무효할지라도 이번처럼 급격한 request의 지연을 초래하는지는 의문스러웠다. 왜냐하면 window scaling이라 함은 window size를 65535 이상으로 확대하고자 하는 메커니즘인데 인터넷과 같이 round-trip이 큰 환경도 아니고서야 throughput에 큰 영향은 없을것이기 때문이다.
Experiment and bizzare result

SYN Cookie에서 window scaling이 무효화 되면 실제로 얼마나 큰 영향이 발생하는지 실험해보기로 했다. 이 실험에서는 net.ipv4.tcp_syncookies 리눅스 커널 파라미터를 2로 설정해 SYN flood 여부와 관계없이 모든 connection을 SYN cookie를 활용해서 수립되도록 한 다음 broker를 restart해 재현을 시도했다.
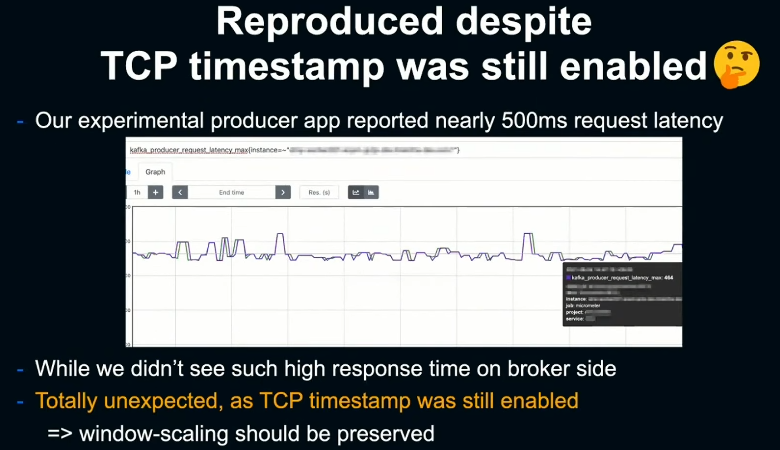
그 결과 전혀 예상하지 못했는데, TCP timestamp를 무효화하기 전부터, 다시 말해 window scaling이 유효해야 할 상태에서 현상이 재현되었다. 실제 환경에서 일어난 현상과 마찬가지로 producer단의 request latency가 500ms 정도의 매우 높은 수치를 보였음에도 불구하고 broker단의 response time은 지극히 정상적인 상태를 유지하고 있었다.
Observation from tcpdump

이 때 tcpdump를 확인해보니 놀랍게도, producer가 패킷을 한번 전송할때마다 broker의 ACK을 기다리고 있던것으로 나타났다. 즉, broker단의 window size가 작아 broker로부터 ACK을 수신하기 까지 producer가 후속 패킷을 송출하지 못하는 상황이 발생하고 있었다. broker단의 window size는 TCP dump를 보면 789로, 실제 window size는 여기에 만큼 곱한 값이다.

마찬가지로 tcpdump에서 SYN+ACK 패킷을 확인해보니 broker가 producer에 advertising한 window scaling factor는 1로 되어 있었다. 다시 말해 실제 window size는 로 매우 작은 값이었다. 그래서 window size가 왜 이렇게 작아졌는지 알아보기로 했다.
Observation from ss

여기서 ss는 소켓의 상태를 확인하기 위한 tool이다. -i 플래그로 window scaling factor와 congestion window size, tcp timestamp 유효 여부등 TCP의 상세정보를 알 수 있다.
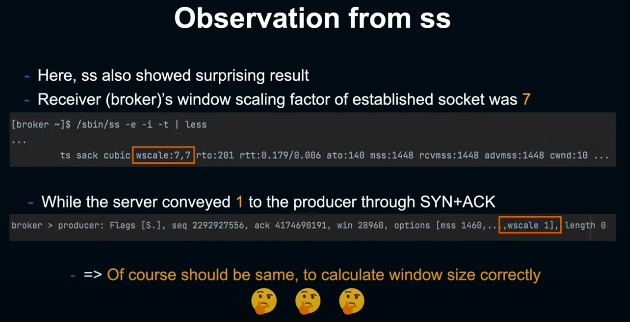
ss를 이슈가 발생한 broker에서 실행해 소켓의 상태를 조사해본 결과, 또 다시 기묘한 현상이 나타났다. ss의 출력을 보면 broker단의 scaling factor가 7로 출력되고 있었던 것이다. 앞서 tcpdump에서 보았듯이 SYN+ACK에서 window scaling factor는 1이어야한다고 producer단에 advertising한 상태였다. 또한 window scaling factor를 사용해 window size를 계산하는 사례에서 보았듯이 client와 server(여기서는 producer와 broker) 양측이 보유한 window scaling factor가 일치하지 않으면 broker가 advertising한 window size를 통해 원래 window size를 정확하게 복원할 수 없기 때문에 당연히 일치해야 한다.
Hooking tcp_select_window w/ BPF

다음으로 실제 broker단에서 advertising 하는 window size를 계산할 때 사용한 값이 1인지 7인지 확인해보기로 했다. 리눅스 커널의 소스코드를 확인해보면 window size의 계산은 tcp_select_window라는 커널 함수에서 담당했다. 이 함수의 인자인 sock 구조체의 window scaling factor가 포함되어 있기 때문에 이것을 hook해서 dump하는 방법을 생각해보았다.

BPF라는 리눅스 시스템을 사용하면 매우 쉽게 커널함수를 hook 할 수 있다. BPF를 사용하면 유저가 작성한 프로그램을 커널 내부에서 실행할 수 있다. BPF는 이벤트로 구동되는 tool로 다양한 이벤트를 트리거삼아 BPF 프로그램을 실행할 수 있다. 이 때 kprobe를 사용하면 임의의 커널함수를 hook할 수 있게 된다. 그리고 BCC(BPF Compiler Collection)이란게 있어 C로 쉽게 BPF 프로그램을 작성할 수도 있다.
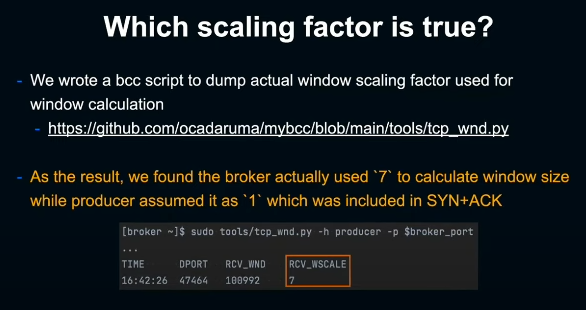
BCC를 사용해 tcp_select_window를 hook하고 window scaling factor를 확인하는 간단한 스크립트를 작성해봤다. 이 스크립트를 broker단에서 실행해보니 실제로 producer에 전송한 1이 아니라 ss가 출력한 7을 사용해 window size를 계산한 것으로 나타났다.
왜 이렇게 broker에서 producer로 SYN+ACK으로 advertising한 window scaling factor와 broker가 실제로 connection을 수립한 이후 사용하는 window scaling factor간의 차이가 발생하는걸까?
Linux Kernel Bug (<5.10)

다시 한번 커널의 소스코드를 확인해보니 window scaling factor를 결정하기 위한 로직이 client에 전송하는 SYN+ACK 패킷을 생성하는 부분과 SYN Cookie를 전송한 후 client가 돌려보낸 ACK에 포함된 SYN Cookie를 디코딩해 connection을 수립하는 부분에서 차이가 있었다.
이는 리눅스 커널 5.10 이전에 발생했던 버그로 이로 인해 window scaling factor에 차이가 발생한것이다.
요약하면 다음과 같다:
-
broker를 restart하면 수많은 client들로부터의 재연결로 인해 SYN flood가 발생한다.
-
결과적으로, 몇몇 producer들은 SYN Cookie를 사용해 TCP connection 수립한다.
-
리눅스 커널 5.10 버전 이전에 발생했던 버그로 인해, broker가 producer에 대해 SYN+ACK으로 advertising한 window scaling factor와 broker가 최종적으로 connection을 수립한 후에 사용하는 window scaling factor에 차이가 발생한다.
-
이 차이로 인해 producer단에서는 broker가 advertising한 window size를 정확하게 복원하지 못하고 매우 작은 값이 된다.
-
즉 broker단에서 producer에 window size를 advertising할때 broker는 window scaling factor를 7로 인지하고 있기 때문에 producer에서 >> 7 처리를 해줄거라 생각하고 로 window size를 나눠 전달한다.
-
한편 producer단에서는 window scaling factor를 1로 인지하고 있기 때문에 을 곱해 window size를 복원하려 한다. 이에 따라 producer에서 계산한 window size가 원래 값의 64분의 1이라는 매우 작은 값이 되버린다.
-
이 너무나도 작은 window size로 인해 producer는 패킷 하나 보낼때마다 broker의 ACK을 기다려야 한다.
-
그 결과 produce request를 송신하는데 상당히 많은 시간이 걸리게 되면서 timeout을 초래한다.
Solution
근본적인 원인이 밝혀졌기에, 어떻게 하면 해결할 수 있을지 생각했다.

먼저 시도해본것은 애초에 TCP SYN Cookie를 무효화 하는것이었다. 이 경우에서 SYN flood는 악의를 가진 client들로 인한게 아니라 broker의 재기동에 따른 client들의 재접속이 실질적으로 공격처럼 작용해서 SYN flood를 초래했을뿐 모든 connection은 정상적인 client들로부터 온 것이었다. SYN Cookie를 무효화하면 SYN flood 동안은 SYN을 drop하게 되는데 모든 client가 정상이기 때문에 곧바로 client단의 SYN retry를 통해 성공적으로 접속할 수 있어 큰 문제가 되지 않았다.
그러나 SYN drop과 SYN retry는 어느정도 지연이 발생할 수 있다. 따라서 SYN Cookie의 무효화와 더불어 Kafka의 listen backlog size를 늘려 애초에 SYN flood 상태가 되지 않도록 하는게 보다 바람직한 해결책이라 할 수 있겠다. 다만 2021/09/29 당시엔 Kafka의 backlog size가 50으로 하드코딩 되어있어 조절할 수 없었다. 진행사항은 KIP-764에서 확인해 볼 수 있다.
세줄 요약
-
LINE의 클러스터와 같이 많은 client가 접속하는 대규모 Kafka 플랫폼에서는 SYN flood가 일어날 수 있다.
-
리눅스 커널 5.10 이전 SYN Cookie 관련 버그로 인해 broker와 producer간 window scaling factor에 차이가 생겨 TCP throughput이 현저하게 악화되는 경우가 있다.
-
이와 같은 커널내부까지의 네트워크 이슈를 조사할 때에는 tcpdump, ss, bcc(BPF) 등의 tool이 매우 유용했다.
이런 것에 관심 있다면 LINE DEVELOPER DAY 2019에 발표한 "Reliability Engineering Behind The Most Trusted Kafka Platform"도 한번 보라고 한다. 지금 하고 있는 일들이 마무리되면 이것도 정리해보고자 한다. 공부하면 공부할수록 멋있는 사람들이 정말 많다. 나도 언젠가 그렇게 되고 싶다.
