📜 문제

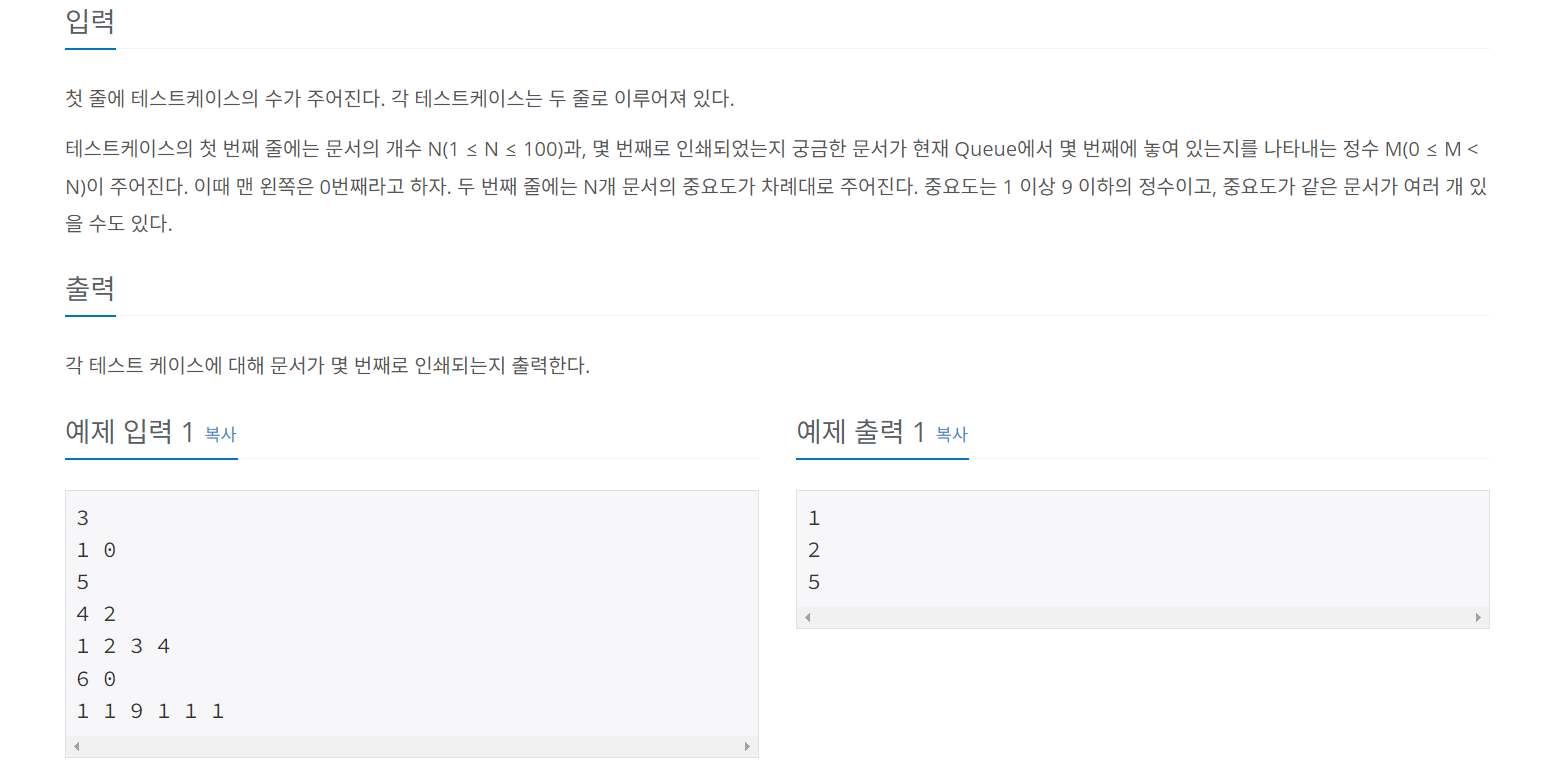
- 첫째줄에는 테스트 케이스의 수, 각 테스트 케이스는 두 줄
- 테스트 케이스
- 첫번째 줄: 문서의 개수, 출력 순서가 궁금한 문서가 위치한 큐의 idx
- 두번째 줄: N개의 문서의 중요도(1<=x<=9), 중요도 중복 허용
✍ 부분 코드 설명
public static void main(String[] args) throws IOException {
BufferedReader br =
new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st;
StringBuilder sb = new StringBuilder();
int testcase = Integer.parseInt(br.readLine());
int i=0;
while(i<testcase) {
...
testcase에 수행할 테스트 케이스를 입력받고, while문으로 해당 testcase만큼 반복한다.
테스트 케이스 입력값 받기
선입선출이 특징인 큐지만, 해당 문제에선 우선순위에 따라 중간에 삭제되는 data가 존재하므로 LinkedList를 사용한다.
while(i<testcase){
LinkedList<Integer> que = new LinkedList<>();
st = new StringTokenizer(br.readLine(), " ");
int pcout = Integer.parseInt(st.nextToken()); // 문서의 개수
int pos = Integer.parseInt(st.nextToken()); // 찾고자 하는 문서의 큐 idx
int count = 1; // 찾는 문서의 인쇄 번째
st = new StringTokenizer(br.readLine()," ");
for(int k=0;k<pcout;k++){ // 큐의 초기 상태
que.addLast(Integer.parseInt(st.nextToken()));
}
...
최우선 데이터 찾기
int maximum = 9; // 최대 중요도 값: 9
while(!que.isEmpty()) {
int max = que.get(0); // 최우선순위 값
int max_idx = 0; // 최 우선순위 인덱스
// 현재 큐에서 최우선순위를 가진 문서 인덱스 찾기
for (int m = 1; m < que.size(); m++) {
if (max < que.get(m)) {
max = que.get(m);
max_idx = m;
if(max == maximum) // 불필요한 반복 최소화
break;
}
else continue;
}
if(max < maximum) maximum =max; // 현재 큐의 최대 중요도값 갱신
// 찾고자하는 문서의 큐 idx와 같은 경우 sb에 추가 및
// 해당 테스트 케이스 종료
if(max_idx == pos){
sb.append(count+"\n");
break;
}
...-
사전에 문서의 최대 중요도는 9라고 명시돼 있다.
maximum 변수에 현재 큐에 남아있는 중요도의 최대값을 저장하여 불필요한 반복을 줄인다.
큐를 순회하면서 가장 큰 중요도를 가진 문서를 발견하면 해당 문서가 제거되므로 뒤의 요소를 검사할 필요가 없음. -
발견된 가장 큰 중요도(max)가 maximum 보다 작은 경우, maximum을 max로 갱신한다.
-
제거될 문서의 인덱스가 찾고자 하는 문서의 인덱스와 같은 경우 앞서 선언한 sb 변수에 해당 번째(count)를 저장한 후 해당 테스트 케이스를 종료한다.
최우선 문서 제거 & pos, 큐 상태 갱신
발견한 문서가 찾고자 하는 문서가 아닌 경우 실행되는 코드이다.
먼저, 찾아낸 문서를 제거하고, 제거된 문서의 idx에 따라 코드를 실행한다.
-
isposChange 변수를 사용해 찾고자 하는 문서의 idx의 갱신 여부를 판별한다.(중복 갱신되는 경우 방지)
-
제거된 문서의 앞문서들은 차례대로 큐의 맨 뒤로 이동한다.
-
앞 문서들 중 찾고자 하는 문서가 있는 경우,
pos를 (현재 큐 크기 - 제거된 문서 인덱스 + 현재 pos) 값으로 갱신하고, isposChange를 true로 변경한다.Why? (예시)
찾고자 하는 문서 위치 (pos): 1제거 전 큐의 상태: 1 2 3 9 1 1 1 (max_idx: 3, pos: 1)
제거 후 큐의 상태: 1 1 1 1 2 3 (size: 6, pos: 4)
pos = 6 - 3 + 1 = 4 (size - max_idx + pos)
que.remove(max_idx); // 최우선순위 문서 제거
if(max_idx>0) {
boolean isposChange = false; // pos의 idx 갱신 여부
// 제거된 최우선순위 문서의 앞 문서들 차례대로 맨 뒤로 이동
for (int m = 0; m < max_idx; m++) {
if (m == pos && !isposChange) {
pos = que.size() - max_idx + pos;
isposChange = true;
}
que.addLast(que.removeFirst()); // 맨 앞 문서 뒤로 이동
}
// 찾고자 하는 문서가 제거된 문서보다 뒤쪽에 있던 경우
if(!isposChange)
pos = pos - max_idx-1;
}
else pos-=1; // 제거된 문서가 맨 앞 문서였던 경우
count++; // 출력 순서: +1
}
...-
찾고자 하는 문서가 제거된 문서보다 뒤에 있는 경우,
pos가 앞당겨지므로 pos = (pos - 제거된 문서의 인덱스 - 1) 값으로 갱신한다.Why? (예시)
찾고자 하는 문서 위치 (pos): 5제거 전 큐의 상태: 1 1 3 9 1 2 1 (max_idx: 3, pos: 5)
제거 후 큐의 상태: 1 2 1 1 1 3 (pos: 1)
pos = 5 - 3 - 1 = 1 (pos - max_idx - 1) -
제거된 문서가 큐의 맨 앞 문서였던 경우,
모든 문서를 한 칸씩 앞으로 당기므로 pos-=1 값으로 갱신한다.
🍳 전체 소스 코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.LinkedList;
import java.util.StringTokenizer;
public class N_1966 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st;
StringBuilder sb = new StringBuilder();
int testcase = Integer.parseInt(br.readLine());
int i=0;
while(i<testcase) {
LinkedList<Integer> que = new LinkedList<>();
st = new StringTokenizer(br.readLine(), " ");
int pcout = Integer.parseInt(st.nextToken()); // 총 문서 개수
int pos = Integer.parseInt(st.nextToken()); // 찾고자 하는 문서의 큐 idx
int count = 1; // 찾는 문서의 인쇄 번째
st = new StringTokenizer(br.readLine()," ");
// 큐의 초기 상태
for(int k=0;k<pcout;k++){
que.addLast(Integer.parseInt(st.nextToken()));
}
int maximum = 9;
while(!que.isEmpty()) {
int max = que.get(0); // 최우선순위 값
int max_idx = 0; // 최 우선순위 인덱스
// 현재 큐에서 최우선순위를 가진 문서 인덱스 찾기
for (int m = 1; m < que.size(); m++) {
if (max < que.get(m)) {
max = que.get(m);
max_idx = m;
if(max == maximum) break;
} else continue;
}
if(max < maximum) maximum =max;
if(max_idx == pos){
sb.append(count+"\n");
break;
}
que.remove(max_idx); // 최우선순위 문서 제거
if(max_idx>0) {
boolean isposChange = false;
// 제거된 최우선순위 앞 문서들 차례대로 맨 뒤로 이동
for (int m = 0; m < max_idx; m++) {
if (m == pos && !isposChange) {
pos = que.size() - max_idx + pos;
isposChange = true;
}
que.addLast(que.removeFirst()); // 맨 앞 수 뒤로 이동
}
if(!isposChange)
pos = pos - max_idx-1;
}
else pos-=1;
count++;
}
i++; // 반복
}
System.out.print(sb);
}
}
✨ 결과
풀고 나서 생각해 보니, 큐를 갱신할 때 찾고자 하는 문서의 갱신 코드를 굳이 반복문 안에 넣지 않고 아래 코드처럼 밖에 빼내면 더 효율적일 것 같다.
if(max_idx>0) {
// 제거된 최우선순위 앞 문서들 차례대로 맨 뒤로 이동
for (int m = 0; m < max_idx; m++) {
que.addLast(que.removeFirst()); // 맨 앞 수 뒤로 이동
}
if (pos < max_idx) {
pos = que.size() - max_idx + pos;
}
else {
pos = pos - max_idx - 1;
}
}
else pos-=1;
count++;