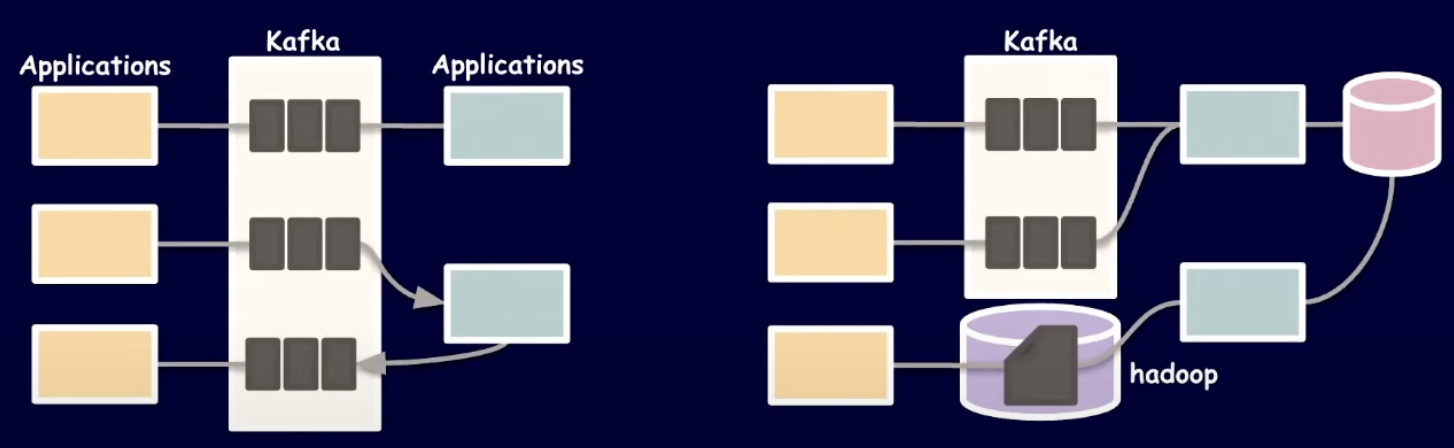
신뢰성 있는 카프카 애플리케이션을 만드는 3가지 방법
이 글은 최원영님의 kakao tech meet 발표를 보고 공부한 내용을 정리한 것 입니다.
Kafka의 사용 이유

EDA(Event Driven Architecture)와 Stram Data Pipeline 에서 중요한 역할을 수행
- 스트림 이벤트를 다뤄 실시간 데이터 처리
- 타임스탬프, 파티션, 메시지 키와 같은 기능들을 활용해 시간 단위 이벤트 데이터를 다룸
Meassage Reliability

- Exactly once (정확히 한 번) : 메시지가 정확히 한번만 전달되는 것을 뜻하며 가장 이상적인 상황이다.
- At least once (적어도 한 번) : 메시지가 적어도 한번은 전달되는 것을 보장하는 것으로 Ack을 받지 못하면 재시도하여 메시지가 중복될 수 있다는 것을 의미한다.
즉, 데이터 유실에는 critical하고 중복에는 tolerable한 서비스에 적합하다. - At most once (최대 한 번) : 메시지가 최대 한번만 전달되는 것으로 Ack을 받지 못해도 무시하고 다음 데이터를 전송한다(빠르다).
즉, 데이터 유실에 tolerable하고 성능이 중요한 서비스에 적합하다.
Producer Acks의 종류
위의 메시지 전달 신뢰성은 Producer Configs의 acks 옵션으로서 구현되어 있다.
| OPTION | Message LOSS | SPEED | DESCRIPTION |
| acks = 0 | 상 | 상 | 프로듀서는 자신이 보낸 메시지에 대해 카프카로부터 확인을 기다리지 않습니다. |
| acks = 1 | 중 | 중 | 프로듀서는 자신이 보낸 메시지에 대해 카프카의 leader가 메시지를 받았는지 기다립니다. follower들은 확인하지 않습니다. leader가 확인응답을 보내고, follower에게 복제가 되기 전에 leader가 fail되면, 해당 메시지는 손실될 수 있습니다. |
| acks = all(-1) | 하 | 하 | 프로듀서는 자신이 보낸 메시지에 대해 카프카의 leader와 follower까지 받았는지 기다립니다. 최소 하나의 복제본까지 처리된 것을 확인하므로 메시지가 손실될 확률은 거의 없습니다. |
Kafka의 메시지 전달 방식

- Producer : Record 단위로 메시지를 발행하여 Acks을 받는 작업을 atomic하게 수행
- Consumer : 현재 Partition offset으로부터 Record 단위로 데이터를 읽고 변경된 offset을 commit 하는 작업을 atomic 하게 수행
문제상황 1 - Brocker Ack 유실

만약 네트워크 장애로 인해 Ack이 유실된다면? (default acks = 1)
-> Ack이 유실되는 수 만큼 레코드 중복 적재
해결 1 - Idempotence(멱등성) producer

데이터의 중복 적재를 막기 위해 enable.idempotence 옵션을 제공하고 Kafka 3.0 버전 이후부터는 default true로 설정된다.
동작 방식은 다음과 같다.
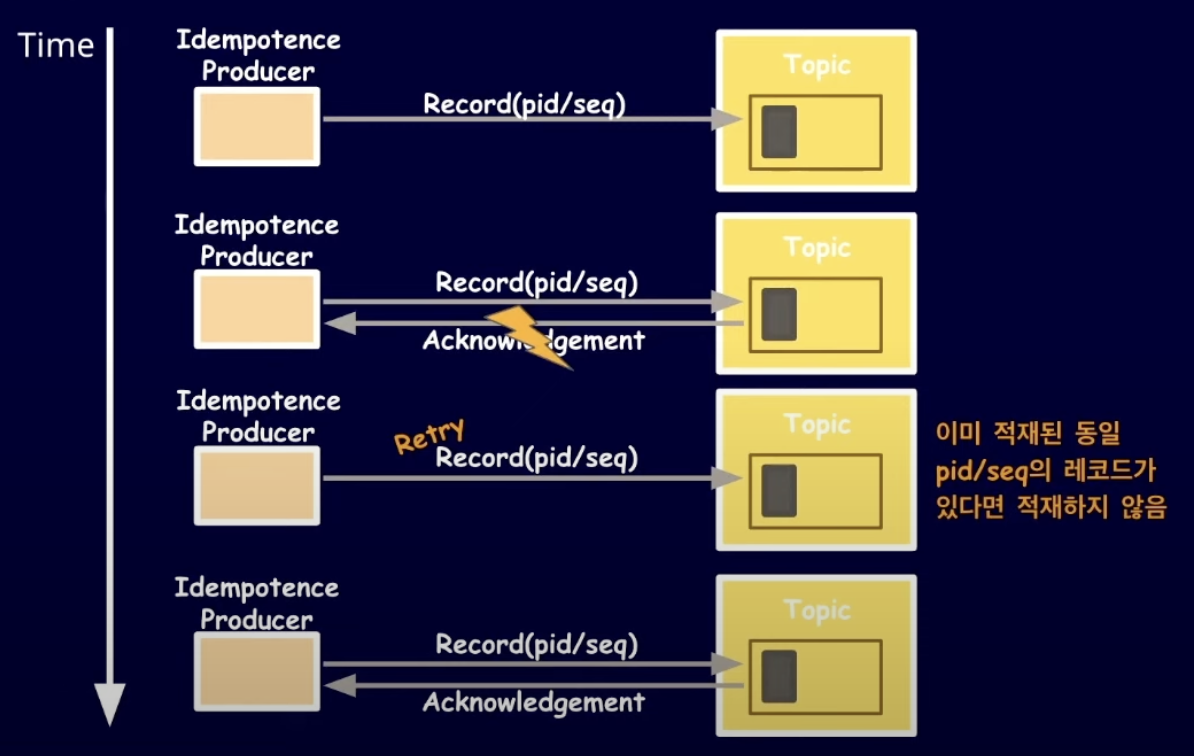
- 멱등성 프로듀서는 레코드를 브로커로 전송할 때 PID(Producer unigue ID)와 Sequence number를 함께 전달
- 브로커는 PID와 Seq를 가지고 중복된 레코드가 오면 무시
문제상황 2 - 컨슈머의 장애에 따른 이벤트 중복 전달
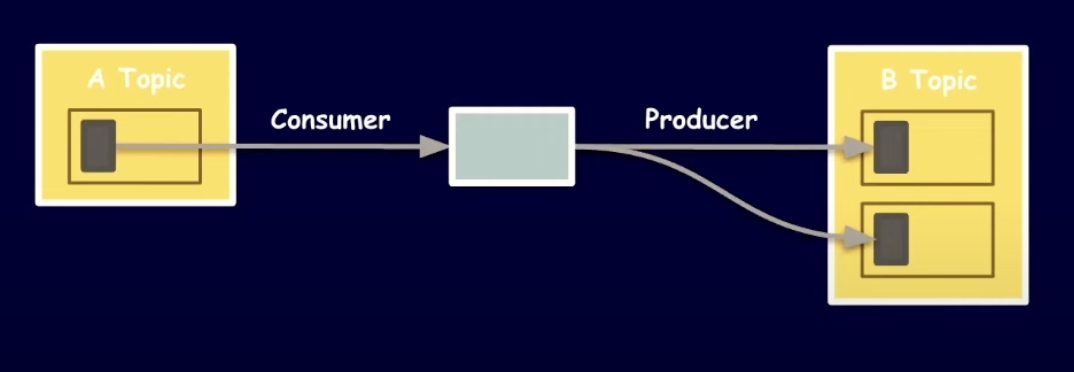
위와 같이 특정 Consumer가 또 다른 Producer가 되어 여러 Topic에 메시지를 발행할 수 있다. (Topic to Topic message delivery)
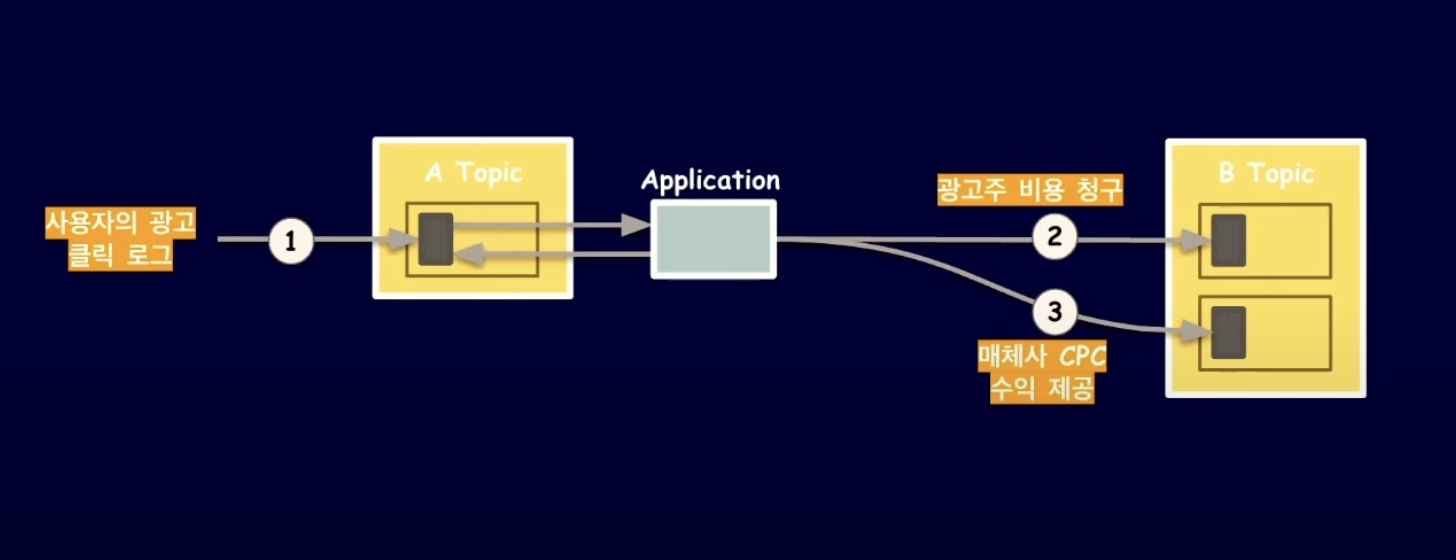
예를 들어, 사용자가 광고를 클릭하면 광고주에게 비용을 청구하고 메체사에는 CPC 수익을 제공해야하는 비즈니스 로직이 있다고 가정.
사용자의 광고 클릭 로그들을 저장하여 이벤트를 발행하고 Application에서 해당 이벤트를 Consume하여 광고주 비용청구 이벤트와 매체사 수익 제공 이벤트를 발행.
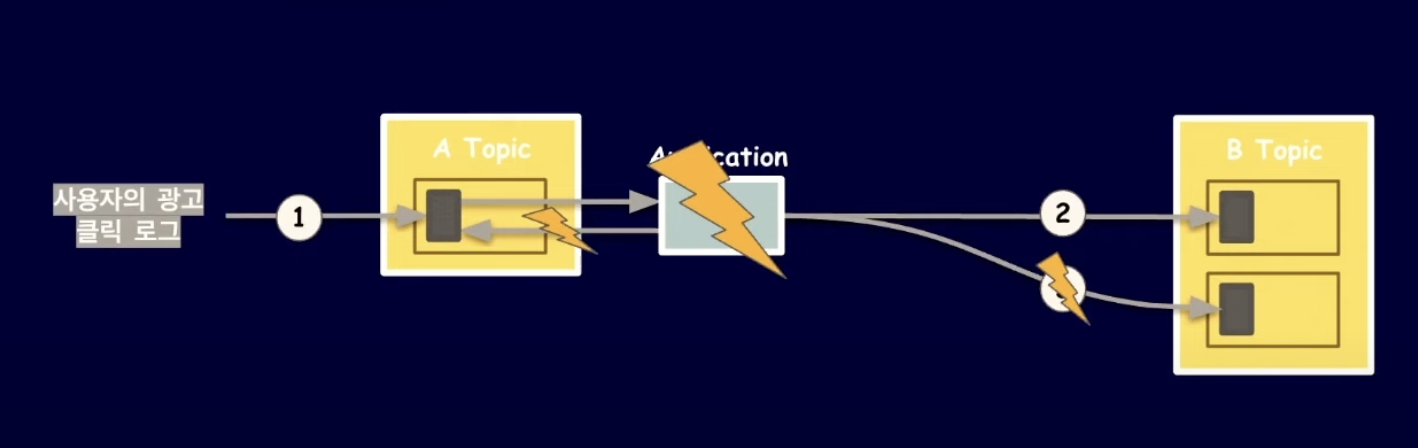
만약 애플리케이션에서 데이터를 처리하고 offset commit 하기전 장애가 발생한다면?
애플리케이션 다시 동작할 때 이미 전달한 레코드를 중복하여 처리하게 됨.
-> Offset commit 과 레코드 전달을 하나로(atomic) 묶어야만 한다!
해결 2 - Transaction Producer

위와 같이 Transaction Producer를 통해서 Consumer가 offset commit하지 않고 Producer가 트랜잭션 내부에서 커밋한다.
다만 주의할점은 Consumer가 자동으로 offset commit 하지 않도록 Consumer 설정을 다음과 같이 변경해줘야 한다.
enable.auto.commit = false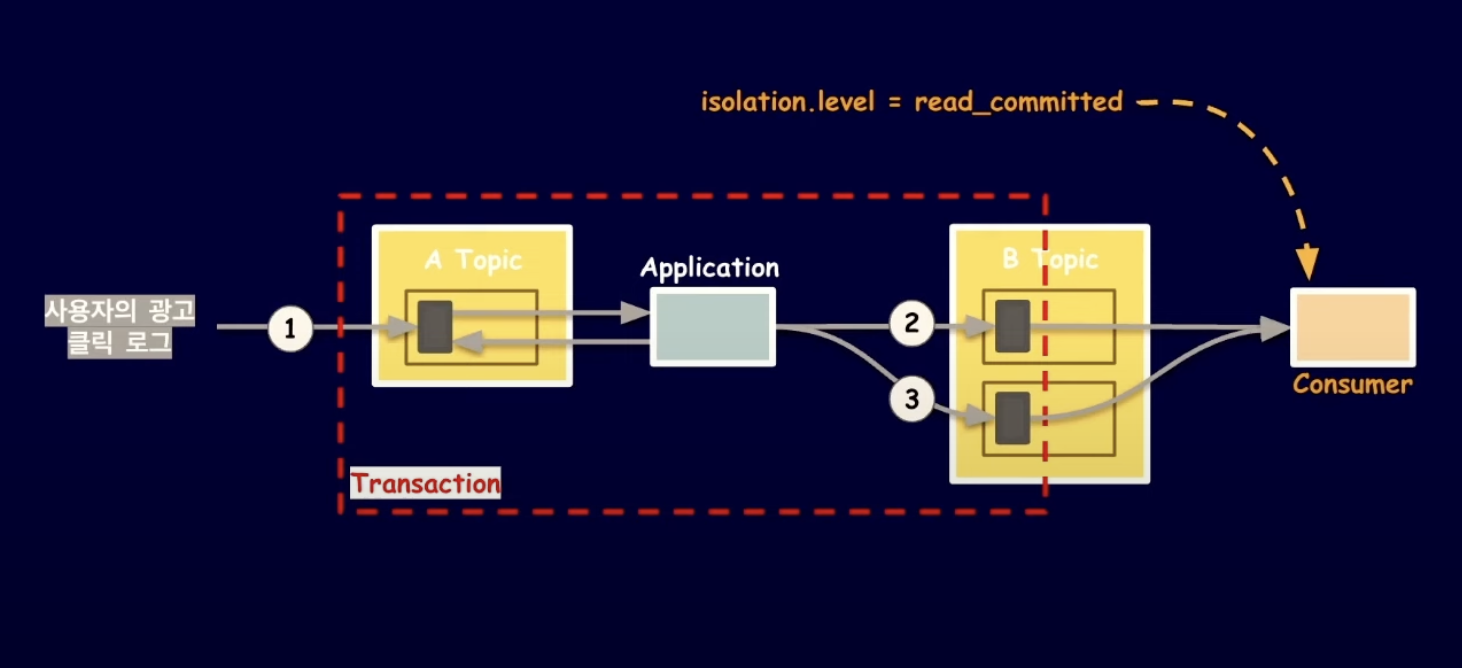
위에 예시를 들었던 서비스에 적용시키면 위와 같이 Consumer가 데이터를 처리하는 작업과 Producer로 다른 topic에 이벤트를 발행하는 작업을 하나의 트랜잭션으로 묶을 수 있다.
여기서 주의할점은 Consumer가 Producer가 커밋한 레코드만 읽을 수 있도록
Consumer의 isolation.level을 default 값인 read_uncommitted에서 read_committed로 변경해줘야 한다는 것이다.
isolation.level = read_committed다만 Comsumer가 트랜잭션이 커밋될 때까지 기다리기 때문에 Letancy가 증가할 우려가 존재한다.
문제상황 3 - 다른 저장소 사용
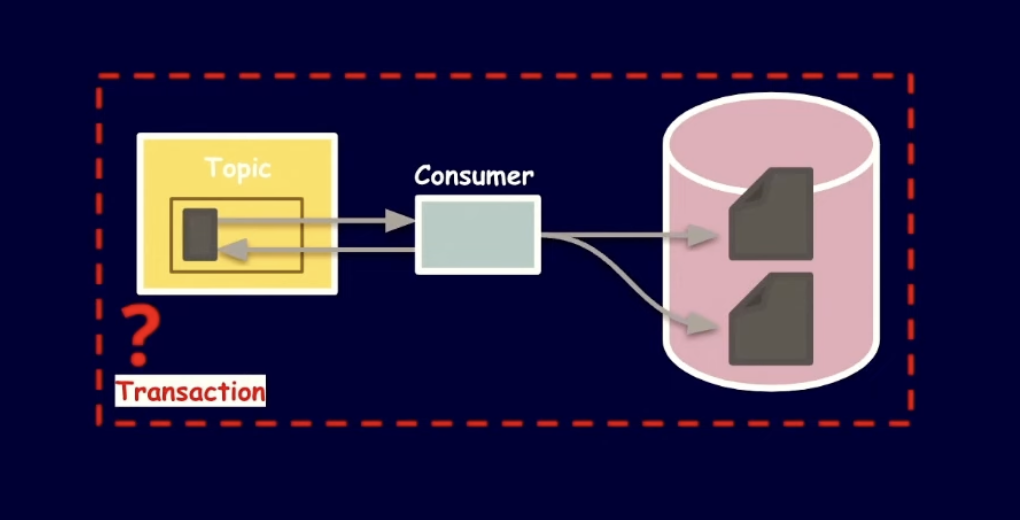
다른 종류의 저장소를 사용할 땐 사실상 하나의 트랜잭션으로 완벽히 보장하긴 거의 불가능하다.
해결 3-1 - Unique Key 활용한 멱등성 컨슈머

타임스탬프와 같은 데이터로 Unique key를 만들어서 중복 적재를 방지.
다만 저장소에서 Unique key 기능을 제공해야 한다.
해결 3-2 - Upsert를 활용한 멱등성 컨슈머
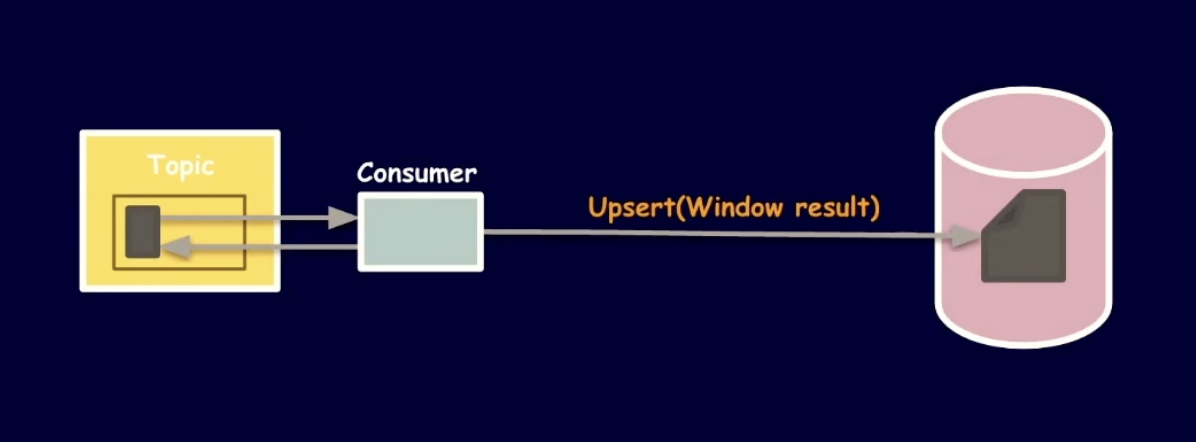
Upsert = Update + Insert
Window result과 같은 중간 결과값들을 일단 저장소에 저장하고 (Key가 없으면 Insert)
최종 결과값으로 Update하는 방식. (Key가 있으면 최종 결과값으로 Update)
해결 3-3 - Write-ahead log를 활용한 컨슈머
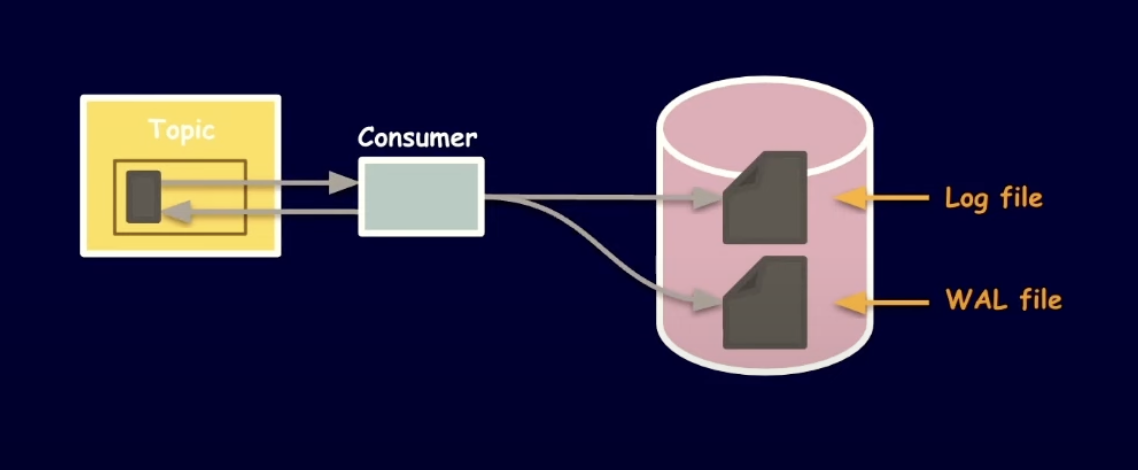
트랜잭션이 커밋되기전에 WAL에 미리 기록하여 적재 과정을 Atomic 하게 보장한다. 중복 적재를 검사할 때 2개의 로그 파일과 Topic offset들을 대조하여 데이터를 확인해야 되기 때문에 로직이 복잡해질 수 있다.
3가지 방법 정리
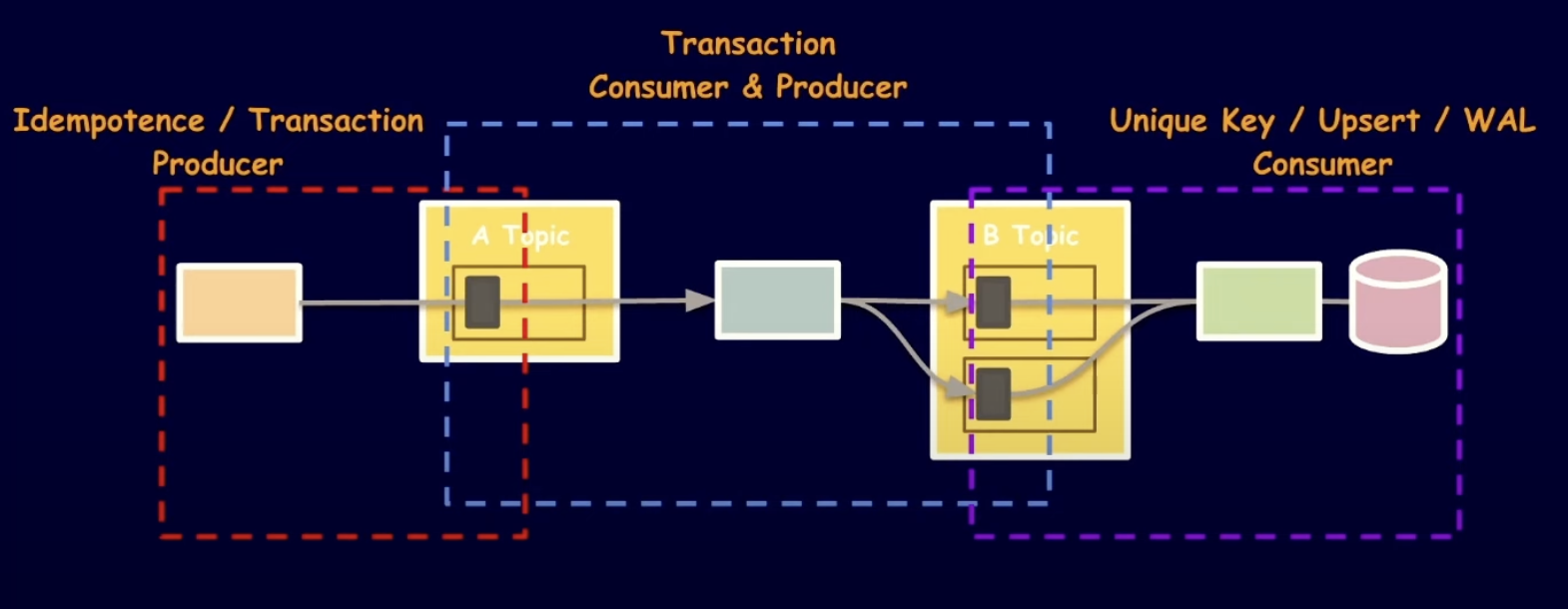
지금까지 나온 해결 방법들을 정리하면
1. Idempotence Producer를 통해 레코드 A Topic 레코드 중복 적재 방지
2. Transaction Consumer & Producer를 통해 B Topic 레코드 중복 적재 방지
3. Unique Key / Upsert / WAL Consumer를 통해 다른 종류 저장소에 데이터 중복 저장 방지
Reference :
https://www.youtube.com/watch?v=7_VdIFH6M6Q&list=WL&index=2&t=1212s
https://www.popit.kr/kafka-%EC%9A%B4%EC%98%81%EC%9E%90%EA%B0%80-%EB%A7%90%ED%95%98%EB%8A%94-producer-acks/
