
Web Browser에 대하여
-
브라우저의 역할
Browsers convert Hypertext Transfer Protocol (HTTP) web pages and websites into human-readable content 1)
위와 같이 브라우저는 HTTP(프로토콜) 웹페이지 혹은 웹 사이트를 사람들이 읽을 수 있는 형태로 렌더링해주는 역할을 한다. 좀더 자세하게 정리를 해보면 다음과 같다.
브라우저의 역할 정리
- HTML 파일을 실행해주는 launcher와 같은 역할을 한다. MS 워드가 docx파일을 실행시켜주듯이, 웹 브라우저는 html 확장자를 실행시켜서 렌더링해준다.
- 위의 과정은 유저로 하여금 World Wide Web에서 유용한 웹사이트(웹 어플리케이션)을 브라우징할 수 있게 해준다.
- 본래 웹 브라우저의 메인 역할은 유저로하여금 인터넷에 접속하여 유용한 정보를 탐색할 수 있게 해주는 것이다.
- URI 검색바, 즐겨찾기 세팅 등 유저 친화적인 기능을 제공한다.
- HTML, CSS, JS Parser가 있어서 서버로부터 데이터를 받아온 뒤에 그것을 파싱하여 렌더링해준다.
- 위와 같은 콘텐츠를 서버에 요청하기 위한 네트워크 모듈도 자체 내장되어있고, 주로 HTTP를 이용해 통신한다.
- 결론적으로 웹브라우저의 메인 역할 2개는 서버에 리소스를 '요청' 하는 것과 서버로부터 리소스를 받아서 그것을 '출력' 하는 것이다.
-
브라우저의 렌더링 과정 (동작 과정)
네이버라는 홈페이지에 접속하는 과정을 예로 설명해보려 한다.- 유저가 브라우저의 '주소 입력창'에 'www.naver.com'을 입력한다(URL을 입력하는 과정).
- 그 URL의 호스트네임이 DNS(Domain Name Server)를 통해 실제 IP주소로 컨버팅되고 이 IP주소에 해당하는 서버에 요청을 보낸다.
- 이 때, www.naver.com처럼 세부 path가 없는 루트 요청을 하게되면 암묵적으로 index.html을(네이버 서버가 제공하는) 응답하도록 설정되어있다(기본).
- 그러면 서버는 이에 대해 response로 index.html를 보내주게 되고, 웹 브라우저는 이를 받아 렌더링을 하게된다(by 웹브라우저's rendering engine) 브라우저의 html parsing 및 DOM 생성 과정 요약
- 브라우저가 웹서버로부터 받은 html파일은 순수 텍스트이기 때문에 브라우저는 이를 자기가 이해할 수 있도록 파싱과정을 거친다.
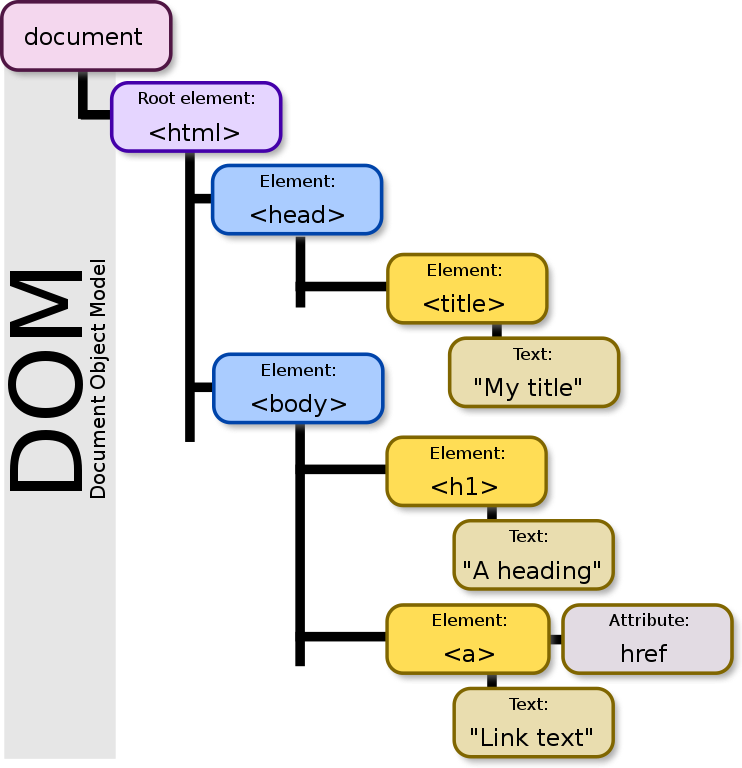
- 그렇게 파싱과정을 거쳐서 본인(브라우저)이 이해할 수 있는 자료 구조인 DOM(Document Object Model)을 생성해서 메모리에 저장한다.
- 가장 먼저, 웹서버로부터 받은 자료는 사실 텍스트도 아닌 byte(이진수)형태의 자료이다
101110101010..... - 이 이진수형태의 자료를 먼저, '문자열'형태로 바꿔야하는데, 그 과정에서 우리가 html문서에 항상 써주는
meta charset="utf-8"의 내용과 같이(response header에 들어있다), utf-8 방식으로 엔코딩해준다. - 그러면 이제야 순수 텍스트인 html을 얻을 수 있다(브라우저가).
<html>형태의 우리가 타이핑하는 코드를 문자열 형태로 얻었다는 것(바이트 자료형에서). - 그러면 이 텍스트를 문법적 의미를 갖는 가장 작은 단위인 토큰(token) 단위로 분해한다.
- 그리고 이렇게 분해한 토큰들을 객체로 변환해서 노드(Node) 들을 생성한다.
- 마지막으로, 위와 같은 노드들(태그, 어트리뷰트, 텍스트 등으로 나뉨)을 바탕으로 각각의 노드들간의 중첩 관계를 반영하여 DOM(Document Object Model)을 트리구조로 생성한다.
- 이렇게까지가 브라우저가 본래 바이트 형태(html)의 자료를 자기가 이해할 수 있는 자료구조 형태로 만들기까지의 과정이다. 그리고 위와 같은 과정을 parsing 이라 한다.
- 렌더링 엔진은 HTML 파싱 과정에서 HTML 파일을 한줄한줄 읽어나간다(순서대로). 그러면서 DOM을 생성해가는데, 이 과정에서 css를 로드하는 link태그나 style 태그를 만나면 DOM 생성을 중단한다.
- 그리고, style 태그 혹은 link 태그로부터 불러온 css를 HTML과 동일한 파싱과정(바이트-> 문자열 -> 토큰 -> 노드 ->CSSOM)을 거쳐 파싱하고, 결과로, DOM이 아닌 CSSOM(CSS Object Model) 을 생성한다.
- 그리고 위의 과정 역시 웹브라우저의 렌더링 엔진이 실행한다.
- 위와 같이 DOM, CSSOM을 생성한 다음에 렌더링 을 위해 렌더트리(render tree) 로 결합된다.
- 이 과정에서 meta 태그, stript 태그 혹은 css의 특성으로 display:none을 해놓은 부분은 반영되지 않는다. 즉, 렌더 트리는 순수하게 렌더링을 위한 자료이다(렌더링 되는 노드들로만 구성!).
- 이렇게 렌더트리가 완성되면, 이를 바탕으로 레이아웃 을 잡고, 픽셀을 렌더링하는 페인트 처리를 한다.
- 이 때, JS를 이벤트 핸들러를 통해 레이아웃이 변했다던지, 브라우저의 뷰포트 크기가 변경된다던지의 변경사항이 생기면 여태까지 DOM, CSSOM, 렌더트리, 레이아웃 및 페인트 과정을 모두 포함하는 렌더링 과정을 한번더 하는 '리렌더링' 과정을 거치게 된다. 이 때, 리렌더링은 필수적인 상황에서만 해야하는데, 이에 대한 비용이 많이드는 작업이기 때문이다. 그렸던 그림을 다 지우고 다시 그리는 데에 쓰이는 시간과 비용을 비유적으로 생각해볼 수 있다.
- 이 과정을 실제로 웹 브라우저의 개발자도구의 네트워크 탭을 통해 살펴볼 수 있는데, 네트워크 탭을 열고 네이버 루트 페이지를 새로고침해보면, 루트 요청으로 받은 html 부분뿐만 아니라 css, js, img, font 등의 파일도 같이 response로 받는 것을 알 수 있다. 이는 브라우저가 html파일을 실행할 때(혹은 렌더링할 때) 그 웹문서 안에 있는 link태그의 css 파일 요청, img 태그의 이미지 요청 등을 만나면 parsing을 중단하고(동기적 처리) 해당 리소스를 요청하기 때문에 렌더링이 되기전에 로딩시간이 생기는 것도 이러한 맥락이다.
- 위의 과정을 거쳐 최종적으로 www.naver.com의 index.html이 웹 브라우저의 뷰포트에 보이게 된다.
CSS 파싱과 CSSOM 생성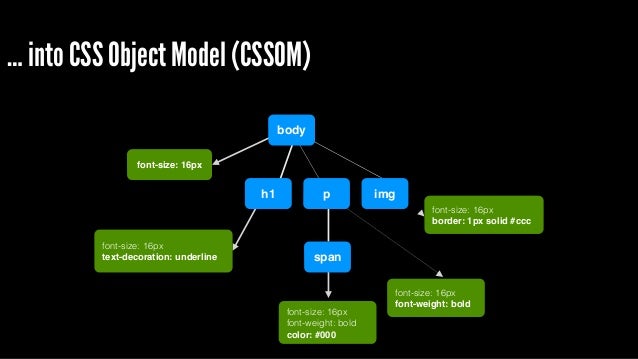
렌더 트리 생성 과정
참고 사이트 및 문헌 : 1) https://www.hubspire.com/resourhttps://developers.google.com/web/fundamentals/performance/critical-rendering-path/render-tree-construction?hl=koces/general/web-browser-concept-and-functions/ 2) https://developers.google.com/web/fundamentals/performance/critical-rendering-path/render-tree-construction?hl=ko 3) '모던 자바스크립트 deep dive' - 38장. 브라우저의 렌더링 과저 부분 일부

완벽함 보다는 최선의 결과를 위해 끊임없이 노력하는 개발자