[FE] Redux-Thunk vs Redux-Saga
FE

Redux Thunk(+ RTK) vs Redux-Saga
: 흔히 redux의 비동기 처리 로직 혹은 사이드 이펙트를 처리하기 위한 용도로 redux-thunk나 redux-saga를 많이 사용한다. 이번 포스팅에서는 앞서 말한 redux와 연관되는 라이브러리가 필요한 이유부터 시작해서 각 라이브러리의 장단점을 가지고 서로를 비교하는 시간을 가져보도록 하겠다. 추가로 redux-thunk에서 나아가 RTK에서 제공하는 새로운 middleware(미들웨어)에 대해서도 알아보고자 한다.
Redux 미들웨어 왜 필요할까?
By itself, a Redux store doesn't know anything about async logic. It only knows how to synchronously dispatch actions, update the state by calling the root reducer function, and notify the UI that something has changed. Any asynchronicity has to happen outside the store.
By redux-official
: 우리는 가장 유명한 라이브러리라서 혹은 프로젝트에 반드시 필요해서 혹은 가장 익숙해서 등 다양한 이유를 갖고 redux를 사용한다(리덕스가 뭔지에 대해서는 설명을 생략한다). 이 때, redux에는 reducer라는 것이 로직에 포함되는데, 그 reducer에는 사이드 이펙트가 없어야 한다는 특징이 있다. redux에서 미들웨어가 필요한 이유에 대해서 납득을(?)하고 넘어가기 위해 그 이유에 대해서 간략하게 짚고 넘어가자.
reducer는 왜 side effect를 허용하지 않을까?
: reducer 안에서 unpredictable한 사이드 이펙트가 발생한다면(예를 들어, api 처리와 같은) 이는 'Predictable state container for JavaScript apps'라는 redux의 정의를 해치게 된다. 하지만 api를 호출한다고 해서, 즉, fetch 로직을 넣는다고 해서(혹은 axios) unpredictable하다는 것이 무슨 의미일까?. 보통 api 요청의 결과는 일단 2가지(success, failure)로 나뉜다. 이 때, 성공을 했다고 해도 그 response 값이 무엇인지 개발자는 알고 있을 수 있지만 사실상 예측할 수 없는 값이된다. 실패의 경우 response를 정해놓았다면 오히려 failure 쪽이더 정확할수도,, 어쨌든 이러한 unpredicatble한 사이드 이펙트를 지양하는 reducer에는 비동기 처리 로직을 넣어서는 안된다. 추가로 api를 호출 했을 때는 새로운 주소값을 가지는 객체 등이 리턴될텐데 얕은 비교를 하는 redux(불변성 때문)의 특징 때문에도 api를 호출해서는 안된다. 결과적으로 reducer를 통해서 state가 실제로 업데이트 되게 되는데, 그 안에서 얕은 비교를 통해 비교 후에 변화가 있으면 새로 적용을 하므로 앞서 말한 사이드 이펙트가 있으면 state 업데이트에 지장을 받을 수 있다.
side effect = 부수 효과 => 부수효과란?
: 예를 들어, 부수효과가 없는 순수 함수는 함수에 동일한 인자가 주어졌을 때 항상 같은 값을 리턴하는 함수 + 외부의 상태를 변경하지 않는 함수를 뜻한다. 항상 같은 값을 리턴하기 위해서는 외부의 값을 참조하지 않아야한다. 만약 참조한다 하더라도 상수(변하지 않는값)를 참조해야 순수 함수이다. 이런게 순수 함수, 즉, 부수 효과가 없는 함수라고 했을 때 부수 효과를 좀 더 잘 이해할 수 있을 것이라고 생각한다.
그렇다면 어떻게 해야할까?
: 앞서 말했듯이 reducer에서는 사이드 이펙트를 일으키는 로직을 쓰지 못한다(예를 들어, 비동기 처리 등). 그에 따라 중간자 역할을(action을 dispatch함으로서 reducer에 전달되는데, 그 사이의 역할을 의미한다 = action과 reducer의 중간) 둬서 그 역할을 대신 수행하도록 해야하는데, 그게 '미들웨어(middleware)'이다. 이 미들웨어에서는 사이드 이펙트가 발생해도 상관없다. 
Redux에서 '비동기 작업을 돕는' middleware에 대해서
: 앞서 제목 부분에서 말한 Redux-thunk와 Redux-saga는 둘 다 Redux에서 ‘비동기 작업을 돕는’ 미들웨어 라이브러리이다.
** 미들웨어란?
a piece of code that sits between your actions and your reducers. It takes your actions does something to it before passing it down to the reducer. Think of it like a middle-man.
: 미들웨어에 대한 설명을 보면 위에서 말한 것과 유사하게 action을 reducer에 dispatch 하기 전에 혹은 전달하기 전에 특정한 액션을 해주는 middle-man 정도로 해석을 하고 있다.
: 다시 돌아와서 그러면 이제 앞서 말한 '비동기 작업을 돕는' 미들웨어인 redux-thunk와 redux-saga에 대해서 알아보자.
redux-thunk vs redux-saga
: 먼저 redux-thunk에 대해서 알아보자.
redux-thunk란?
미들웨어를 사용하면 액션 객체가 아닌 함수를 디스패치할 수 있다
: redux-thunk에 대해서 가장 잘 설명한 문장을 가져와봤다. redux를 써봤다면 알 수 있는게 redux는 state를 action을 reducer에 dispatch해서 컨트롤 한다. 그러면 reducer의 변경사항을 subscribe하던 UI 부분에 변화가 일어나는 구조이다. 그러면 redux-thunk는 action과 reducer 사이에서 어떤 역할을 해줄까를 보면, action을 dispatch 할 때 reducer에 닿기전에 또하나의 객체를 dispatch해준다. 그리고 이 때 그 객체는 함수다. 여기서 redux-thunk가 dispatcher의 개념을 모호하게 만드는 측면이 있다고 생각한다. 본래 액션 객체는 말그대로 {} 이런 형태의 객체를 말하는데, 함수도 일급 객체이긴 하지만 일관성 측면에서 봤을 때 dispatch 안에 함수를 넣을 수 있다고? 생각이 들게 한다(달리 표현하면 액션 생성자는 본래 객체만 리턴하는데, 함수도 만들어서 리턴할 수 있게되는 것 그리고 이처럼 함수를 리턴하는 액션 생성자를 thunk라고 하기도함). 어쨌든, redux-thunk는 함수를 dispatch하게 해줌으로서 그 함수 내부에 axios or fetch 등의 비동기 로직을 쓸 수 있게 해준다. 앞서 말했듯이 reducer 내부에서는 비동기 로직을 쓰지 못하기 때문에 reducer에 도착하기전에(?) redux-thunk라는 middle-man(미들웨어)을 이용해 비동기 처리 로직을 끝내놓고, 결국 reducer에는 똑같이 액션 객체가 도착해서 state 업데이트 로직을 처리하는 식으로 이뤄진다. 아래는 thunk를 일반 js 코드로 표현해본 이미지이다.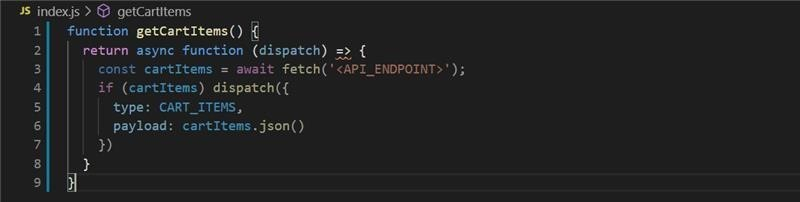 출처 : https://www.eternussolutions.com/2020/12/21/redux-thunk-redux-saga/
출처 : https://www.eternussolutions.com/2020/12/21/redux-thunk-redux-saga/
: 다음으로 redux-saga에 대해서 알아보자.
redux-saga란?
: redux-thunk가 '함수를 디스패치할 수 있게 해주는' 미들웨어였다면, saga는 액션을 모니터링하고 있다가 특정 액션이 발생했을 때, 미리 정해둔 로직에 따라 특정 작업이 이루어지는 액션에 대한 리스너(Listener)이다. 좀 더 풀어서 설명해보면, redux-saga는 특정한 action을 모니터링(주시하고 있다가라고 표현해도 될듯)하고 있다가 해당 action이 실제로 발생했을 때 특정 작업을 하는 방식이다. saga는 먼저 watcher saga & worker saga로 나뉜다(코드적인 측면에서)
const fetchTodo = (url) => fetch(url).then((res) => res.json());
function* workerSaga(action) {
const { url } = action.payload;
try {
const todo = yield call(fetchTodo, url);
yield put(addTodo(todo));
} catch (error) {
yield put(setError({ error }));
}
};
function* watcherSaga() {
yield takeEvery(fetchTodo.toString(), workerSaga);
};위와 같이 saga는 workerSaga & watcherSaga로 나뉜다. watcherSaga는 action이 디스패치 되는것을 살피는 saga이고, workerSaga는 살핀 것을 통해 들어온 input을 판단하여 실제로 그에 따라 처리해야되는 로직을 실행하는 부분이다. 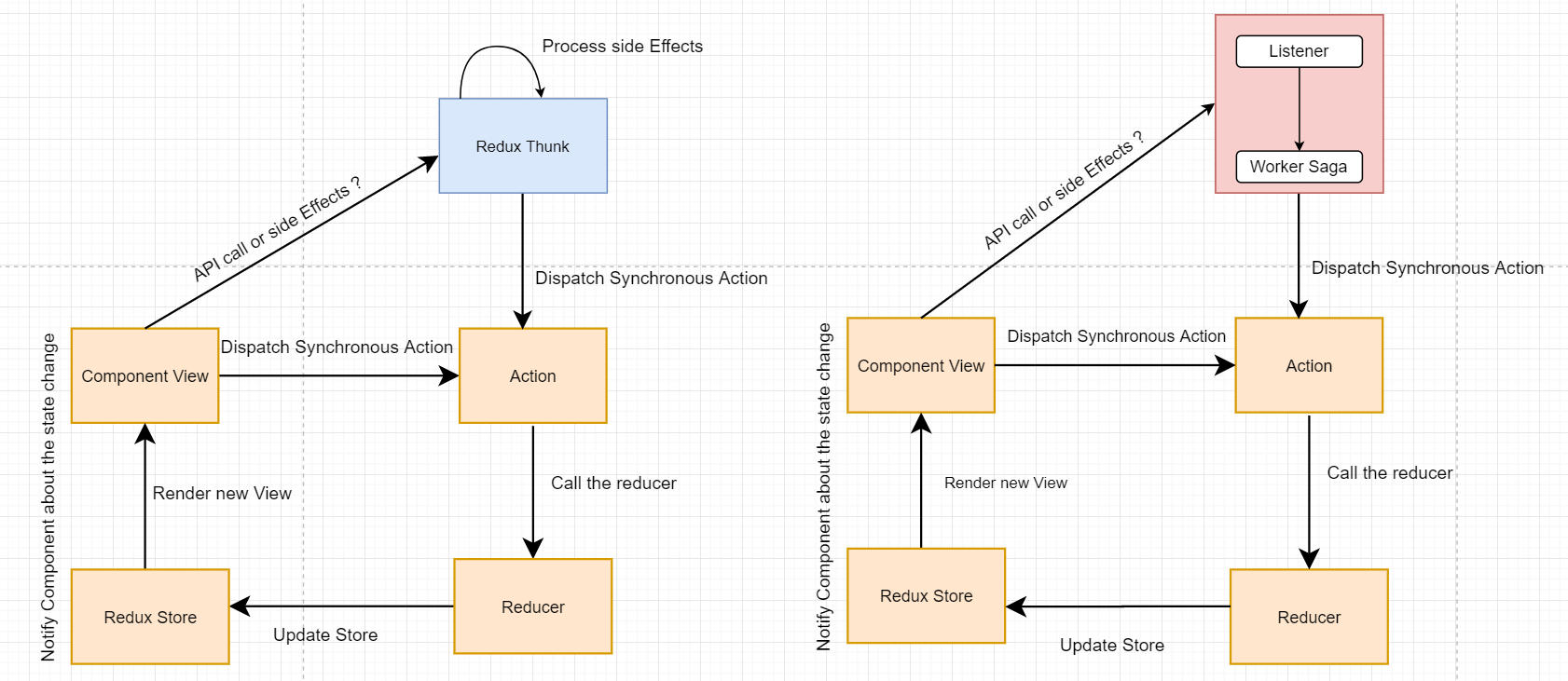 출처 : https://www.eternussolutions.com/2020/12/21/redux-thunk-redux-saga/
출처 : https://www.eternussolutions.com/2020/12/21/redux-thunk-redux-saga/
redux-saga vs redux-thunk 비교
| redux-thunk | redux-saga |
|---|---|
| 적은 boilerplate code | 많은 boilerplate code |
| redux-saga와 비교했을 때 상대적으로 낮은 러닝커브 | ES6의 generator 문법에 대한 능숙함 없이는 처음에 어려울 수 있음 |
| action creator가 함수를 리턴하는 등 순수성을 잃는 단점 | action creator의 순수성 유지 가능 |
| 상대적으로 테스팅이 어려움 | 테스팅이 redux-thunk에 비해 상대적으로 쉬움 |
| async/await를 쓰면 코드가 간결하긴 하지만, saga가 제공하는 effects들을 직접 구현해야 하거나 구현 불가능 | effects(yield, call, throttle, debounce, takeLatest 등)를 이용해서 좀 더 간결한 코드 유지 가능 |
: 위에처럼 정리를 해봤는데, 사실 나는 두개의 라이브러리 모두를 하나의 프로젝트에 적용해본 경험이 있기에 내가 느낀 바로는
- redux-thunk 는 redux-saga에 비해 러닝커브가 현저히 낮다. 그 이유는 redux-saga를 쓸 줄 알려면 혹은 능숙하게 쓸 수 있으려면 ES6의 generator 문법에 대해서 능숙하게 알고 있어야 하기 때문이다. 물론 이부분에 대해서 숙지가 된 팀이라면 고려 대상이 아니지만 한명의 팀원이라도 generator 문법이 익숙치 않다면 redux-saga를 선택하는데에 있어 고민점이 생길만한 특징인 것 같다.
- redux-saga가 제공하는 effects 들을 써서 복잡한 로직을 좀 더 간결한 코드로 혹은 간결한 발상으로 처리할 수 있다. 예를 들어, A라는 액션이 dispatch 됐을 때, 분기 처리를 해둔 다음에 B, C 액션을 다시 디스패치하는 식으로 로직을 쉽게 짤 수 있다(연쇄 작용을 만들 수 있다라고 표현해도 될듯). 앞서 말한 예시와 같은 로직 처리를 redux-saga에서는 effects들을 제공해줌으로서 redux-thunk에 비해 쉽게 표현할 수 있도록 해준다. 반면, redux-thunk 에서는 그러한 effects들을 제공하지 않기 때문에 앞서 말한 로직들을 구현하고 싶다면 직접 코딩을 통해 논리를 짜야하고, 굉장히 코드가 복잡해지고, 지저분해질 수 있다.
: 인터넷을 검색해보면 뭐 중소규모의 프로젝트에는 redux-thunk 를 쓰고, 대규모 플젝에는 redux-saga를 쓰라는 말들이 있던데, 이건 개발자들이 기획자 분들과 회의를 거친 뒤에 해당 프로젝트에 들어가는 로직들을 파악해서 결정하는게 맞다고 생각한다. 사실 둘은 대체재 관계긴하지만, 상호보완적으로 사용할수도 있는 라이브러리이기 때문에 해당 프로젝트에 맞는 방향으로 적절히 써도 될 것 같다. 마지막으로 개인적으로 redux-saga를 쓰면서 좋았던 점은 로그 등을 쌓는 작업을 할 때 A라는 action이 디스패치 됐을 때 연쇄적으로 B라는 로그를 쌓는 액션을 디스패치 하는게 상당히 편리하고 쉬웠다. 즉, 연쇄적인 작업을 설계할 때 redux-saga가 제공하는 인터페이스(?)가 상당히 매력적이었던 기억이 있다.
PS : 다음 포스팅에서는 RTK에서 제공하는 middleware와 redux-saga를 비교해보기로 한다.
